CSAPP相关若干问题的补充整理
内存映射的概念,mmap()的使用
- 内存映射文件技术是操作系统提供的一种新的文件数据存取机制,利用内存映射文件技术,系统可以在内存空间中为文件保留一部分空间,并将文件映射到这块保留空间,一旦文件被映射后,操作系统将管理页映射缓冲以及高速缓冲等任务,而不需要调用分配、释放内存块和文件输入/输出的API函数,也不需要自己提供任何缓冲算法。
- 使用内存映射文件处理存储于磁盘上的文件时,将不必再对文件执行I/O 操作,这意味着在对文件进行处理时将不必再为文件申请并分配缓存,所有的文件缓存操作均由系统直接管理,由于取消了将文件数据加载到内存、数据从内存到文件的回写以及释放内存块等步骤,使得内存映射文件在处理大数据量的文件时能起到相当重要的作用。Memory Mapping是进行文件I/O的高效方法。
在linux中,如果通过malloc()来申请一块大的内存,C库就会在memory mapping segment中创建一个匿名memory mapping而不是使用堆空间。这里的“大”意味着大于MMAP_THRESHOLD字节,该阈值可以通过mallopt()来进行调整。
mmap()将一个文件或者其它对象映射进内存。文件被映射到多个页上,如果文件的大小不是所有页的大小之和,最后一个页不被使用的空间将会清零。mmap()在用户空间映射调用系统中作用很大。
头文件
<sys/mman.h>
原型
void* mmap(void* start,size_t length,int prot,int flags,int fd,off_t offset);
int munmap(void* start,size_t length);
参数说明
start:映射区的开始地址,设置为0时表示由系统决定映射区的起始地址。
length:映射区的长度。//长度单位是 以字节为单位,不足一内存页按一内存页处理
prot:期望的内存保护标志,不能与文件的打开模式冲突。是以下的某个值,可以通过or运算合理地组合在一起
| 值 | 解释 |
|---|---|
| PROT_EXEC | 页内容可以被执行 |
| PROT_READ | 页内容可以被读取 |
| PROT_WRITE | 页可以被写入 |
| PROT_NONE | 页不可访问 |
flags:指定映射对象的类型,映射选项和映射页是否可以共享。它的值可以是一个或者多个以下位的组合体
MAP_FIXED、MAP_SHARED、MAP_PRIVATE、MAP_DENYWRITE、MAP_EXECUTABLE、MAP_NORESERVE、MAP_LOCKED、MAP_GROWSDOWN、MAP_ANONYMOUS、MAP_ANON、MAP_FILE、MAP_32BIT、MAP_POPULATE、MAP_NONBLOCK。
fd:有效的文件描述符。一般是由open()函数返回,其值也可以设置为-1,此时需要指定flags参数中的MAP_ANON,表明进行的是匿名映射。
offset:被映射对象内容的起点。
BitMap:基于位的映射
优点:
运算效率高,不许进行比较和移位;
占用内存少,比如N=10000000;只需占用内存为N/8=1250000Byte=1.25M。
缺点:所有的数据不能重复。即不可对重复的数据进行排序和查找。
BitMap可以使用在CSAPP的malloc lab中时,和链表相结合。举例说明,对于size>=512 Bytes的空闲块,使用传统的链表方法进行组织;其余较小空闲块,使用BitMap标记。将size<512 Bytes的空闲块,分为大小为32、 64、96……480、512的固定块,每种大小空闲块的数量也是预先设定好的,且使用各自的BitMap来标记某空闲块是否已分配。这是某种意义上的32Bytes对齐,是为了做到,可以根据一个块的地址,确定该块的大小和在对应BitMap的比特位。分配时,采用向上取整的策略 ,不拆分空白块。
程序内存映像结构
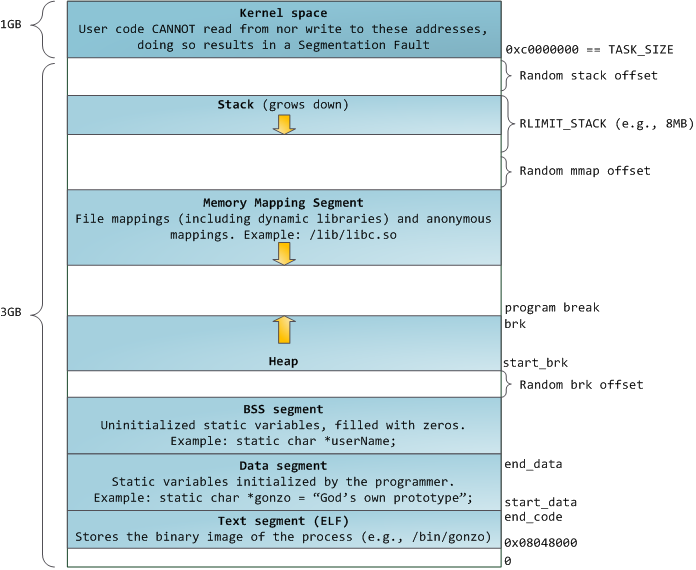
代码段 Text Segment
这里存放的是CPU要执行的指令。代码段是可共享的,相同的代码在内存中只会有一个拷贝,同时这个段是只读的,防止程序由于错误而修改自身的指令。
初始化数据段 Data Segment
这里存放的是程序中需要明确赋初始值的变量。例如初始化为非0的全局变量。
BSS(Block Started by Symbol)段 BSS Segment
未初始化,以及初始化为0或null的变量。
堆 Heap
堆提供了程序运行时的内存分配,C语言中,堆内存分配接口是malloc()及相关函数。除此之外,堆内存空间可以通过brk()系统调用来增长,以便有足够的空间来分配。地址增大,堆变大。
内存映射段 Memory Mapping Segment
这里被内核用来把文件内容直接映射到内存。可以使用linux提供的mmap()来进行这样的映射。地址增大,Memory Mapping Segment变大。
栈 Stack
函数中的局部变量以及在函数调用过程中产生的临时变量都保存在此段中。进程中的每个线程都有自己的栈。地址减小,栈变大。
shell如何实现重定向和pipe
使用dup2进行重定向
头文件<unistd.h>
int dup2(int oldfd, int newfd);
dup2可以用参数newfd指定新文件描述符的数值。若参数newfd已经被程序使用,则系统就会将newfd所指的文件关闭,若newfd等于oldfd,则返回newfd,而不关闭newfd所指的文件。dup2所复制的文件描述符与原来的文件描述符共享各种文件状态。共享所有的锁定,读写位置和各项权限或flags等。
在shell的重定向功能中,(输入重定向”<”和输出重定向”>”)就是通过调用dup或dup2函数对标准输入和标准输出的操作来实现的。
dup2(fd, 1);命令即是使用fd指定的文件来替代标准输出。
实现pipe
管道命令操作符是:| ,它能处理前面一个指令传出的正确输出信息,也就是standard output的信息,将其传递给下一个命令,作为标准输入standard input。它仅能处理standard output的信息,对于standard error信息没有直接处理能力。
在每个|后面接的第一个数据必定是『命令』,而且这个命令必须要能够接受standard input的数据才行。
常用:
| 命令 | 功能 |
|---|---|
| cut | 选取命令。从一行数据中取出想要的部分,选取信息通常以“行”来分析,并不是整篇信息分析的。 |
| grep | 选取命令。分析一行信息,若当中有感兴趣的信息,就将该行拿出来,可以用于正则表达式。 |
| sort | 排序命令。根据不同的数据类型进行排序,排序的字符与语系的编码有关。 |
| wc | 排序命令。常用于统计一个目录中包含多少文件(多少行,多少字,多少字符)。 |
| uniq | 排序命令。这个命令用来将重复的行删除掉只显示一个,需要配合排序过的文件来处理。 |
| tee | 双向重定向。tee会同时将数据流分送到文件去与屏幕(screen);而输出到屏幕的,其实就是stdout,可以让下个命令继续处理。 |
| tr | 字符转换命令。tr可以用来删除一段信息当中的文字,或者是进行文字信息的替换。 |
| col | 字符转换命令。将tab键转换成对等的空格键。 |
| join | 字符转换命令。处理两个文件之间的数据。两个文件当中,有 “相同数据” 的那一行,加在一起。 |
| paste | 字符转换命令。将两行贴在一起,且中间以[tab]键隔开。 |
| expand | 字符转换命令。将[tab]按键转成空格键。 |
| split | 切割命令。如果文件太大,可以使用split将一个大文件依据文件大小或行数来切割成为小文件。 |
| xargs | 参数代换。读入 stdin 的数据,并且以空格符或断行字符作为分辨,将stdin的数据分隔成为arguments。 |
| 减号- | 在管道命令中,经常会用到前一个命令的stdout作为这次的stdin,某些命令需要用到文件名来进行处理时,该stdin与stdout可以利用减号“-”来替代。 |
cat 2.txt | sort | uniq -i |
pipe()可用于创建一个管道,以实现进程间的通信。
头文件<unistd.h>
函数原型int pipe(int fd[2]);
通过pipe()创建的这两个文件描述符fd[0]和fd[1]分别构成管道的两端,往fd[1]写入的数据可以从fd[0]读出。并且fd[1]一端只能进行写操作,fd[0]一端只能进行读操作,不能反过来使用。要实现双向数据传输,可以使用两个管道。向管道读写数据其实是在读写内核缓冲区。
pipe与重定向区别
pipe:左边的命令应该有标准输出 | 右边的命令应该接受标准输入
重定向:左边的命令应该有标准输出 > 右边只能是文件;左边的命令应该需要标准输入 < 右边只能是文件
管道触发两个子进程执行”|”两边的程序;而重定向是在一个进程内执行。
syscall和system library
常用syscall
| Name | Description |
|---|---|
| read | Read file |
| write | Write file |
| open | Open file |
| close | Close file |
| stat | Get info about file |
| mmap | Map memory page to file |
| brk | Reset the top of the heap |
| dup2 | Copy file descriptor |
| pause | Suspend process until signal arrives |
| alarm | Schedule delivery of alarm signal |
| getpid | Get process ID |
| fork | Create process |
| execve | Execute a program |
| _exit | Terminate process |
| wait4 | Wait for a process to terminate |
| kill | Send signal to a process |
exit()和_exit()两个函数都是用于函数退出,但这两者有一些细微的差别,在exit()函数里会调用_exit()函数。exit()和_exit()的区别在于,exit()会首先将函数进行调用以后再退出,而_exit()是直接结束进程。
fork和execve
对于fork():
- 子进程复制父进程的所有进程内存到其内存地址空间中。父、子进程的“数据段”,“堆栈段”和“代码段”完全相同,即子进程中的每一个字节都和父进程一样。
- 子进程的当前工作目录、umask掩码值和父进程相同,fork()之前父进程打开的文件描述符,在子进程中同样打开,并且都指向相同的文件表项。
- 子进程拥有自己的进程ID。
对于exec():
- 进程调用exec()后,将在同一块进程内存里用一个新程序来代替调用exec()的那个进程,新程序代替当前进程映像,当前进程的“数据段”,“堆栈段”和“代码段”背新程序改写。
- 新程序会保持调用exec()进程的ID不变。
- 调用exec()之前打开打开的描述字继续打开(好像有什么参数可以令打开的描述字在新程序中关闭)。
参数列表的保存结构
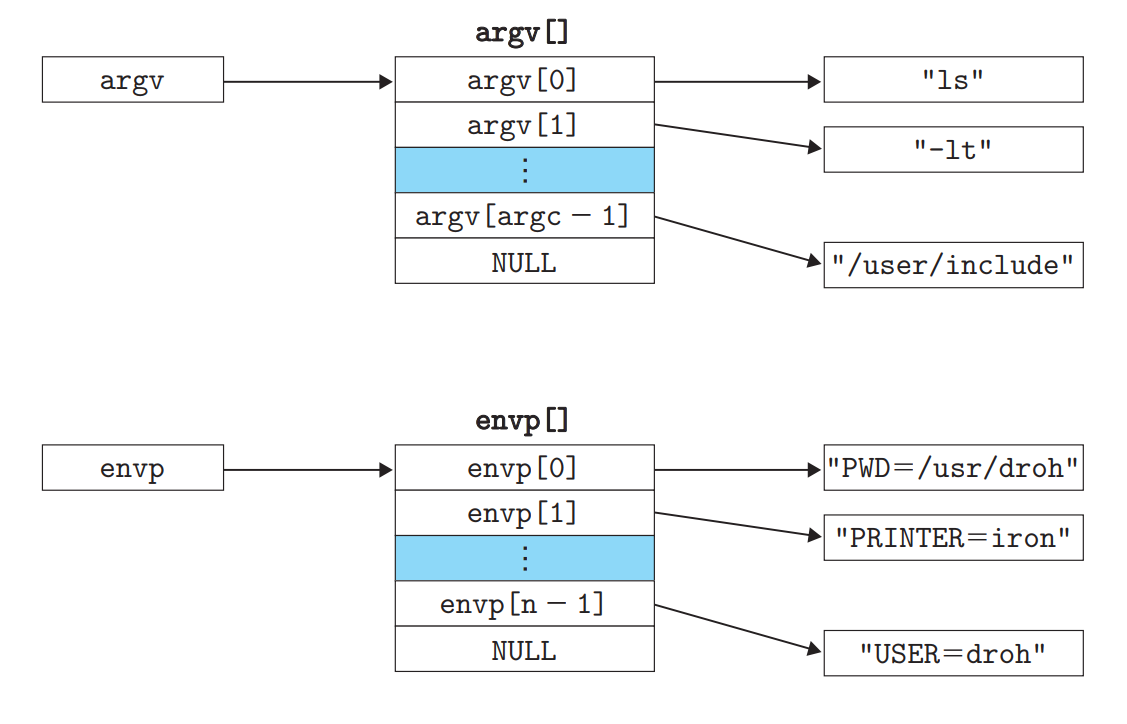
当main开始执行时,用户栈的组织结构如下图。
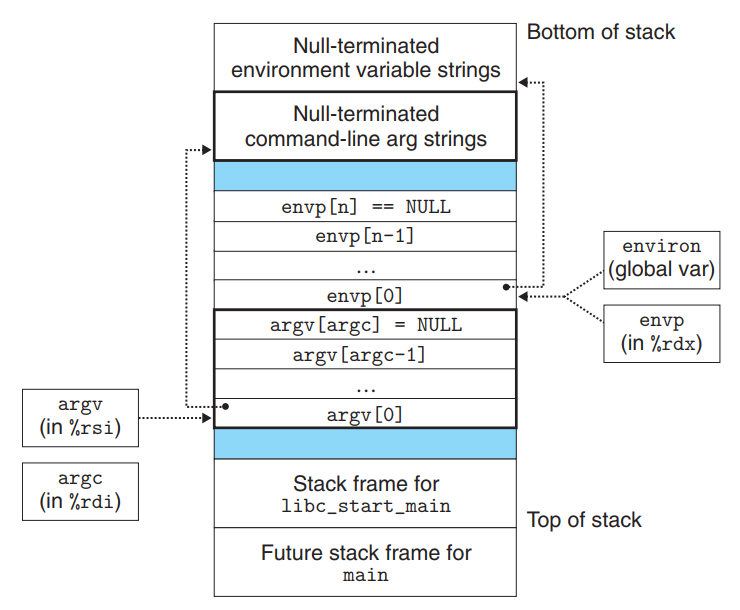
从栈底往栈顶(高地址到低地址)依次看。首先是参数和环境字符串。再向上,是以null结尾的env指针数组(每个指针都指向一个env字符串),然后是arg指针数组(同理)。栈顶是系统启动函数libc_start_main。
使用shell执行ls时涉及哪些syscall
和解析其他指令一样,会用到进程控制相关的fork()、execve()、getpid()、exit(),以及信号相关的sigprocmask()、*sigblock()和kill()等。除此之外,还有readdir()读取目录项和stat()获取文件状态信息。
system library
/usr/include/sys是一个系统库。sys/是系统调用函数头文件的前缀,这些头文件包含的函数,是syscall系统调用。
#include<sys/xxxxxx.h>
例如,定位sys/signal.h,可以发现很多sys目录 |
ABI和API
ABI:Application Binary Interface,应用程序二进制接口。
API:Application Programming Interface,应用程序编程接口。
ABI定义了一套编译应用程序所需要遵循的规则。主要包括基本数据类型,通用寄存器的使用,参数的传递规则,以及堆栈的使用等等和可执行代码二进制兼容性相关的内容。
API是一些预先定义的接口(如函数、HTTP接口),或指软件系统不同组成部分衔接的约定。 用来提供应用程序与开发人员基于某软件或硬件得以访问的一组例程,而又无需访问源码,或理解内部工作机制的细节。
Runtime的概念
编程语境中,Runtime有很多含义,例如:
指「程序运行的时候」,即程序生命周期中的一个阶段。例句:「Rust 比 C 更容易将错误发现在编译时而非运行时。」
指「运行时库」,即 glibc 这类原生语言的标准库。例句:「C 程序的 malloc 函数实现需要由运行时提供。」
指「运行时系统」,即某门语言的宿主环境。例句:「Node.js 是一个 JavaScript 的运行时。」
含义一:程序生命周期中的阶段
程序的编译阶段是 compile time,链接阶段是 link time,那运行起来的阶段自然就是 run time 了。如果在前面的阶段预先做了通常在后面才方便做的事,我们就管这个叫 ahead of time。
含义二:运行时库(runtime library)
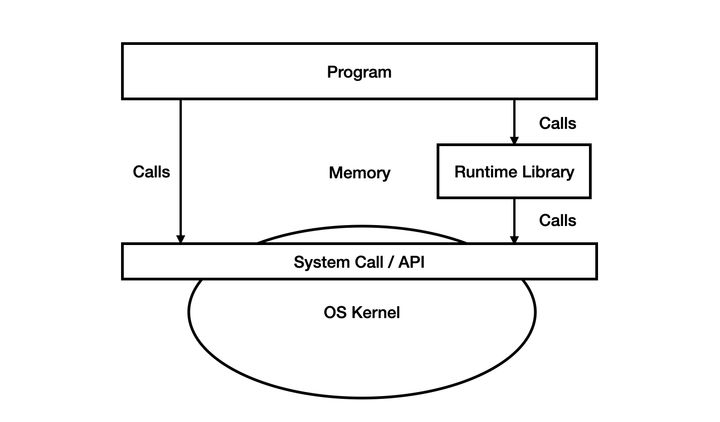
运行时库并不只是标准库,就算不显式include任何标准库,也有一些额外的代码会被编译器插入到最后的可执行文件里。比如main函数,它在真正执行前就需要大量来自运行时库的辅助。哪有什么include进来一把梭的岁月静好,还有编译器和运行时替你默默负重前行。
含义三:运行时系统(runtime system)
上面介绍的运行时库,主要针对的是C、C++和Rust这些「系统级语言」。只要将这个概念继续推广到其他高级语言,这时候的「运行时」指的就是runtime system了——如果讨论某门高级语言的运行时,我们通常是在讨论一个更重、更大而全的运行时库。比如Java的运行时是JRE,C#的运行时是CLR。这两者都相当于一个需要在OS上单独安装的软件,借助它们来解释执行相应语言的程序(编译出的字节码)。相比上面C语言的「运行时」,这已经是个复杂的基础软件系统了。
内核态和用户态区别
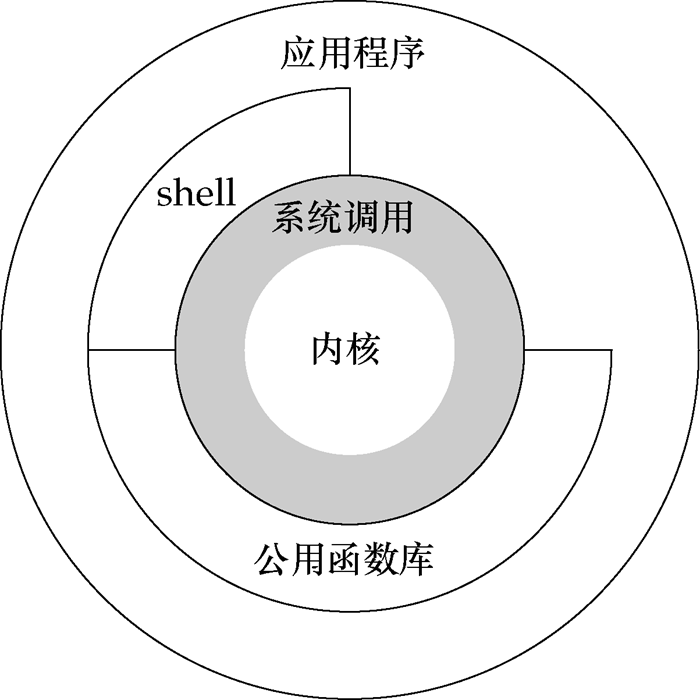
用户态即上层应用程序的活动空间,应用程序的执行必须依托于内核提供的资源,包括CPU资源、存储资源、I/O资源等。为了使上层应用能够访问到这些资源,内核必须为上层应用提供访问的接口:即系统调用。
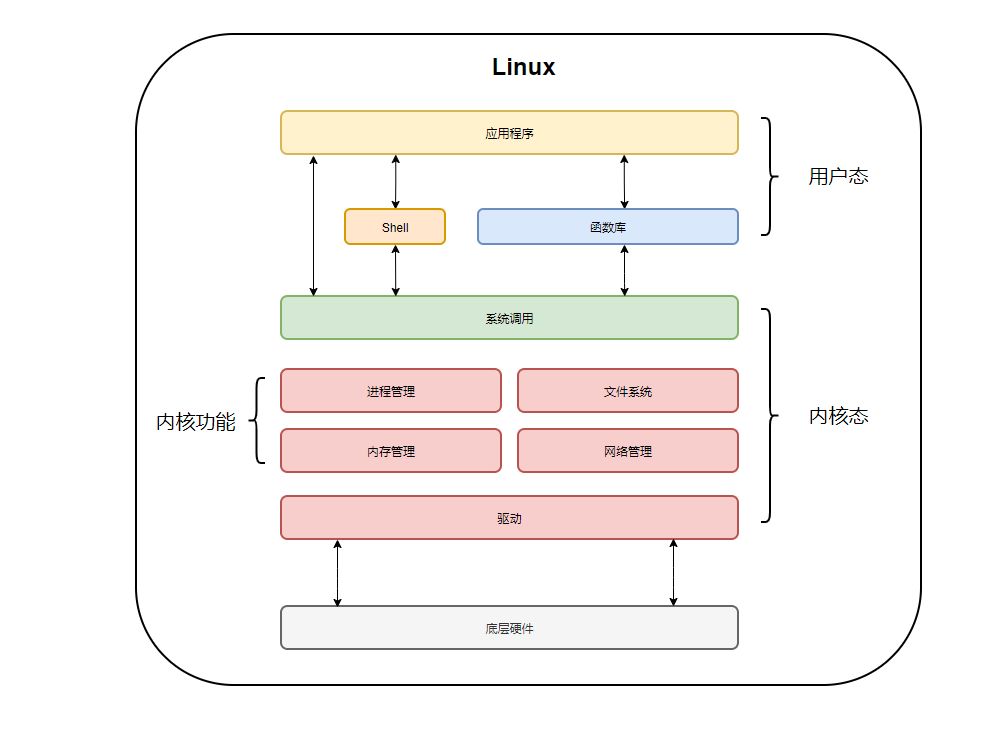
用户态的应用程序可以通过三种方式来访问内核态的资源:系统调用、库函数、Shell脚本。
切换
对不同的操作赋予不同的执行等级,就是所谓特权的概念。简单说就是有多大能力做多大的事,与系统相关的一些特别关键的操作必须由最高特权的程序来完成。运行于用户态的进程可以执行的操作和访问的资源都会受到极大的限制,而运行在内核态的进程则可以执行任何操作并且在资源的使用上没有限制。很多程序开始时运行于用户态,但在执行的过程中,一些操作需要在内核权限下才能执行,这就涉及到一个从用户态切换到内核态的过程。
用户态切换到内核态的3种方式:
系统调用
这是用户态进程主动要求切换到内核态的一种方式,用户态进程通过系统调用申请使用操作系统提供的服务程序完成工作,比如fork()实际上就是执行了一个创建新进程的系统调用。而系统调用的机制其核心还是使用了操作系统为用户特别开放的一个中断来实现。
异常
当CPU在执行运行在用户态下的程序时,发生了某些事先不可知的异常,这时会触发由当前运行进程切换到处理此异常的内核相关程序中,也就转到了内核态,比如缺页异常。
外围设备的中断
当外围设备完成用户请求的操作后,会向CPU发出相应的中断信号,这时CPU会暂执行下一条即将要执行的指令转而去执行与中断信号对应的处理程序,如果先前执行的指令是用户态下的程序,那么这个转换的过程自然也就发生了由用户态到内核态的切换。比如硬盘读写操作完成,系统会切换到硬盘读写的中断处理程序中执行后续操作等。
这3种方式是系统在运行时由用户态转到内核态的最主要方式,其中系统调用可以认为是用户进程主动发起的,异常和外围设备中断则是被动的。
 alipay
alipay