CS140 - Pintos Projects
课程链接
https://web.stanford.edu/~ouster/cgi-bin/cs140-spring20/pintosProjects.php
参考
https://www.cnblogs.com/laiy/p/pintos_project1_thread.html
https://blog.csdn.net/weixin_43752953/article/details/90248966
https://blog.csdn.net/weixin_41680909/article/details/91440122
bochs+pintos
到bochs下载地址下载对应版本后,解压,配置,编译,安装。
wget https://udomain.dl.sourceforge.net/project/bochs/bochs/2.7/bochs-2.7.tar.gz |
报错处理
.bochsrc:197: cpu directive malformed. |
打开.bochsrc配置文件,根据行号找到对应错误处。bochs -help cpu 将显示出所有支持的CPU类型。将.bochsrc文件中cpu:model=core2+penryn_t9600的值为上一条查到的所支持的CPU类型之一。
.bochsrc:956: Bochs is not compiled with lowlevel sound support |
打开.bochsrc配置文件,注释掉文件中的sound: driver=default, waveout=/dev/dsp. wavein=, midiout=语句。同理,可以注释掉下面的speaker相关配置语句。
安装pintos
wget https://web.stanford.edu/class/cs140/projects/pintos/pintos.tar.gz |
遇到权限问题,bochs也各种莫名报错,改bochs为qemu后也疯狂报错。如MoTTY X11 proxy: Unsupported authorisation protocol等。应该是和图形界面相关的什么错。
改Ubuntu虚拟机再从头试试。
qemu+pintos
参考
https://stackoverflow.com/questions/60696354/cloning-pintos-with-ubuntu
https://blog.csdn.net/geeeeeker/article/details/108104466
https://github.com/kumardeepakr3/PINTOS-Ubuntu
步骤
安装好虚拟机和必须的gcc和g++等,就可以正式开始安装pintos。
首先安装qemu作为模拟器。
sudo apt-get install qemu |
然后从pintos官方库中获取最新的pintos,可以避免一些莫名的bug。这一步当然需要先安装git。
git clone git://pintos-os.org/pintos-anon pintos |
然后编辑./pintos/src/utils/pintos-gdb,将GDBMACROS改为系统中对应路径。xxx为示例用户名。
GDBMACROS=/home/xxx/pintos/src/misc/gdb-macros |
这时候在utils文件夹中make,会报错找不到stropts.h。很多人也遇到了这个问题,可能是Ubuntu系统版本的问题,参考中所使用的18.04没有出现该问题。只有一个文件中的几行代码会用到这个库,先注释掉这部分继续编译,后续有问题的话再考虑重新安装Ubuntu18.04。
然后编辑/pintos/src/threads/Make.vars,在第7行左右更改模拟器bochs为qemu。再在/src/threads中make编译线程目录。
紧接着编辑/pintos/src/utils/pintos:
- 103行左右:替换bochs为qemu
- 621行左右:替换模拟器命令为qemu-system-x86_64
- 257行左右:替换kernel.bin为完整路径的kernel.bin(threads目录中的kernel.bin)
- 362行左右:替换$loader_fn变量为完整路径的loader.bin(threads目录中的loader.bin)
编辑~/.bashrc,将/pintos/src/utils添加到PATH,即添加如下命令到最后一行。再重新打开终端运行source ~/.bashrc。
export PATH=/home/.../pintos/src/utils:$PATH |
最后在终端输入pintos run alarm-multiple测试,显示如下。

Alarm Clock
Reimplement timer_sleep(), defined in devices/timer.c. Although a working implementation is provided, it “busy waits,” that is, it spins in a loop checking the current time and calling thread_yield() until enough time has gone by. Reimplement it to avoid busy waiting.
Function: void timer_sleep (int64_t ticks)
Suspends execution of the calling thread until time has advanced by at least x timer ticks. Unless the system is otherwise idle, the thread need not wake up after exactly x ticks. Just put it on the ready queue after they have waited for the right amount of time.
timer_sleep()is useful for threads that operate in real-time, e.g. for blinking the cursor once per second.The argument totimer_sleep()is expressed in timer ticks, not in milliseconds or any another unit. There areTIMER_FREQtimer ticks per second, whereTIMER_FREQis a macro defined indevices/timer.h. The default value is 100. We don’t recommend changing this value, because any change is likely to cause many of the tests to fail.
Separate functions timer_msleep(), timer_usleep(), and timer_nsleep() do exist for sleeping a specific number of milliseconds, microseconds, or nanoseconds, respectively, but these will call timer_sleep() automatically when necessary. You do not need to modify them.
If your delays seem too short or too long, reread the explanation of the -r option to pintos (see section 1.1.4 Debugging versus Testing).
review
主要看devices/timer.c、threads/interrupt.c和threads/thread.c这几个文件。
timer_sleep中,timer_ticks函数获取ticks的当前值返回。intr_get_level返回了intr_level的值。
timer_ticks: Returns the number of timer ticks since the OS booted。从pintos被启动开始,ticks就一直在计时。其中中断相关的语句只是确保这个过程不能被中断,即保持这个操作的原子性。
intr_disable获取了当前的中断状态,然后将当前中断状态改为不能被中断,然后返回执行之前的中断状态。
ASSERT (!intr_context ());断言了intr_context函数返回结果的false,即断言这个中断不是外中断(IO等,也称为硬中断),而是操作系统正常线程切换流程里的内中断(也称为软中断)。
thread_schedule_tail获取当前线程,分配恢复之前执行的状态和现场,如果当前线程死了就清空资源。
thread_yield把当前线程扔到就绪队列里,然后重新schedule。
总结:timer_sleep就是在ticks时间内,如果线程处于running状态就不断把他扔到就绪队列不让他执行。缺点是线程依然不断在cpu就绪队列和running队列之间来回,占用了cpu资源,我们希望用一种唤醒机制来实现这个函数。
实现思路:调用timer_sleep的时候直接把线程block掉,然后在线程结构体中加一个成员ticks_blocked,用于记录线程被sleep了多久。再利用操作系统自身的,每个tick会执行一次的,时钟中断来检测线程状态。每个tick将ticks_blocked减,如果减到0就表示该线程结束sleep,唤醒这个线程。
devices/timer.c
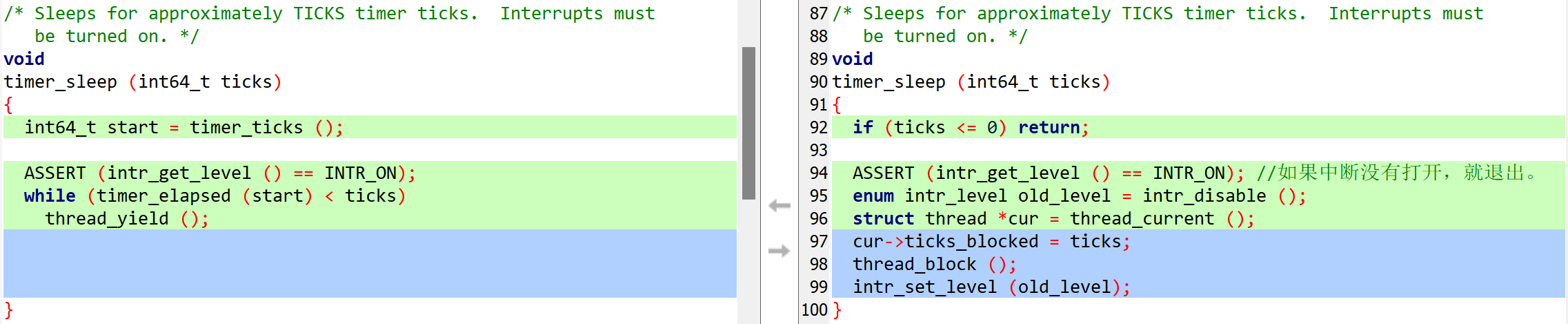
使用old_level保存和恢复中断情况,保证中间操作的原子性。获取当前线程后,设置该线程的ticks_blocked值,并调用thread_block()。

对于系统自身的中断程序,每个tick的时候对每个线程都执行一次blocked_thread_check(借助foreach函数)。
threads/thread.h
在thread中加入ticks_blocked成员。
int64_t ticks_blocked; /* Record the time the thread has been blocked. */ |
声明上文提到的blocked_thread_check函数。
void blocked_thread_check (struct thread *t, void *aux UNUSED); |
threads/thread.c
/* Check the blocked thread */ |
检查是否应该唤醒当前线程。如果该线程状态为Blocked且ticks_blocke值不为0,就将其ticks_blocked递减,如果递减后为0,说明已经sleep到了设定时间,立即将其唤醒。
测试
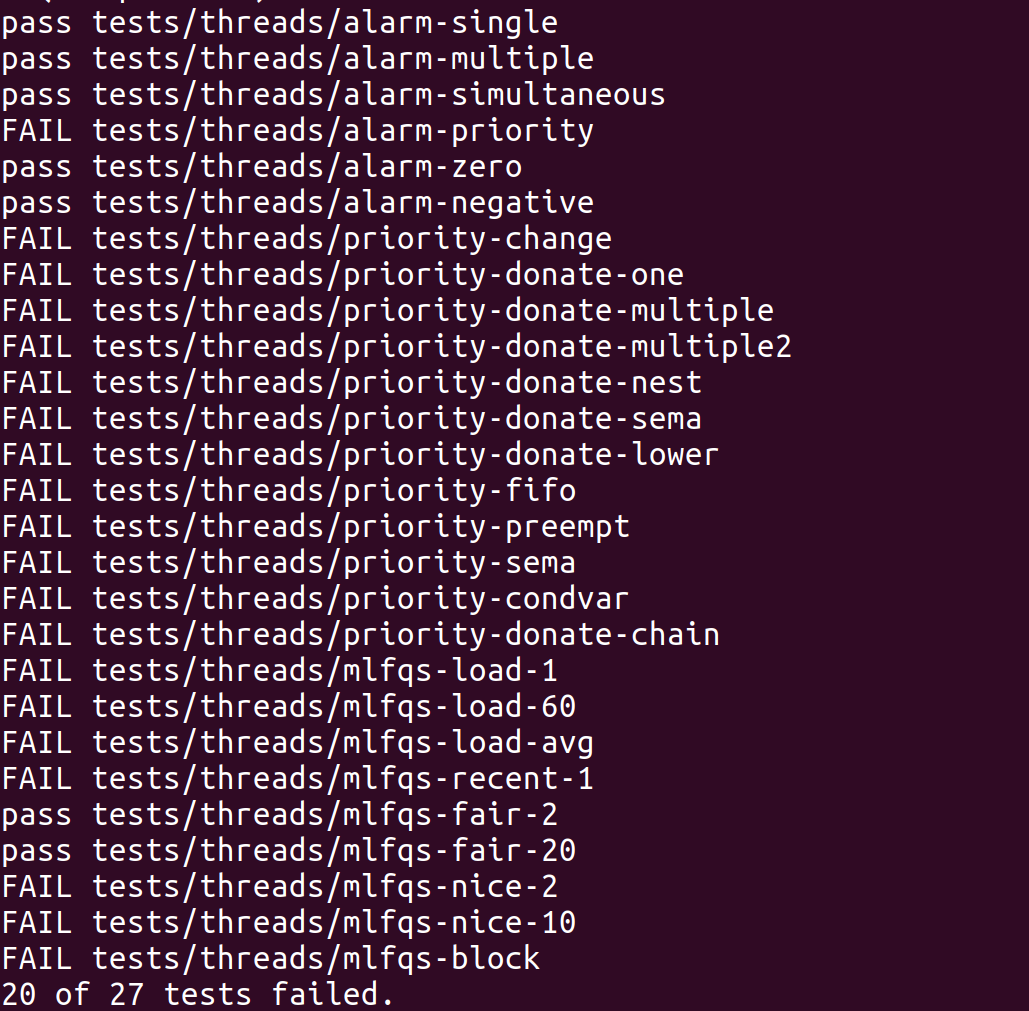
在threads目录中执行make check可以执行所有测试。
Priority Scheduling
Implement priority scheduling in Pintos. When a thread is added to the ready list that has a higher priority than the currently running thread, the current thread should immediately yield the processor to the new thread. Similarly, when threads are waiting for a lock, semaphore, or condition variable, the highest priority waiting thread should be awakened first. A thread may raise or lower its own priority at any time, but lowering its priority such that it no longer has the highest priority must cause it to immediately yield the CPU.
Thread priorities range from PRI_MIN (0) to PRI_MAX (63). Lower numbers correspond to lower priorities, so that priority 0 is the lowest priority and priority 63 is the highest. The initial thread priority is passed as an argument to thread_create(). If there’s no reason to choose another priority, use PRI_DEFAULT (31). The PRI_ macros are defined in threads/thread.h, and you should not change their values.
One issue with priority scheduling is “priority inversion”. Consider high, medium, and low priority threads H, M, and L, respectively. If H needs to wait for L (for instance, for a lock held by L), and M is on the ready list, then H will never get the CPU because the low priority thread will not get any CPU time. A partial fix for this problem is for H to “donate” its priority to L while L is holding the lock, then recall the donation once L releases (and thus H acquires) the lock.
Implement priority donation. You will need to account for all different situations in which priority donation is required. Be sure to handle multiple donations, in which multiple priorities are donated to a single thread. You must also handle nested donation: if H is waiting on a lock that M holds and M is waiting on a lock that L holds, then both M and L should be boosted to H’s priority. If necessary, you may impose a reasonable limit on depth of nested priority donation, such as 8 levels.
You must implement priority donation for locks. You need not implement priority donation for the other Pintos synchronization constructs. You do need to implement priority scheduling in all cases.
Finally, implement the following functions that allow a thread to examine and modify its own priority. Skeletons for these functions are provided in threads/thread.c.
Function: void thread_set_priority (int new_priority)
Sets the current thread’s priority to new_priority. If the current thread no longer has the highest priority, yields.
Function: int thread_get_priority (void)
Returns the current thread’s priority. In the presence of priority donation, returns the higher (donated) priority.
You need not provide any interface to allow a thread to directly modify other threads’ priorities.
review
线程结构体本身就有一个priority,其取值范围被限定为[0, 63],默认值是31。维护就绪队列为一个优先队列可以实现优先级调度。查看源码可以发现thread_unblock、thread_yield函数中有将线程放入ready_list的操作。
查看lib/kernel/list.h文件,发现提供了可以用来维护有序队列的函数。
/* Operations on lists with ordered elements. */ |
pass alarm-priority
// list_push_back (&ready_list, &t->elem); |
将两处list_push_back改写为list_insert_ordered即可。比较函数thread_cmp_priority是自定义的,把优先级数值大的,即优先级大的线程放前面。
/* priority compare function. */ |
list_entry(LIST_ELEM, STRUCT, MEMBER)定义为((STRUCT *) ((uint8_t *) &(LIST_ELEM)->next - offsetof (STRUCT, MEMBER.next))),即将指向list元素list_ELEM的指针转换为指向嵌入list_ELEM的结构体的指针。
这样就通过了alarm-priority测试。
pass priority-change
在某些时候调用thread_yield即可,即把当前线程丢到ready_list中,重新schedule,保证执行顺序。
- 在
thread_create中创建线程的时候, 如果新线程比当前线程优先级高的话,调用thread_yield。 - 在设置任意一个线程优先级时,调用
thread_yield,立即重新考虑所有线程执行顺序。

测试
同时通过了priority_preempt和priority_fifo。
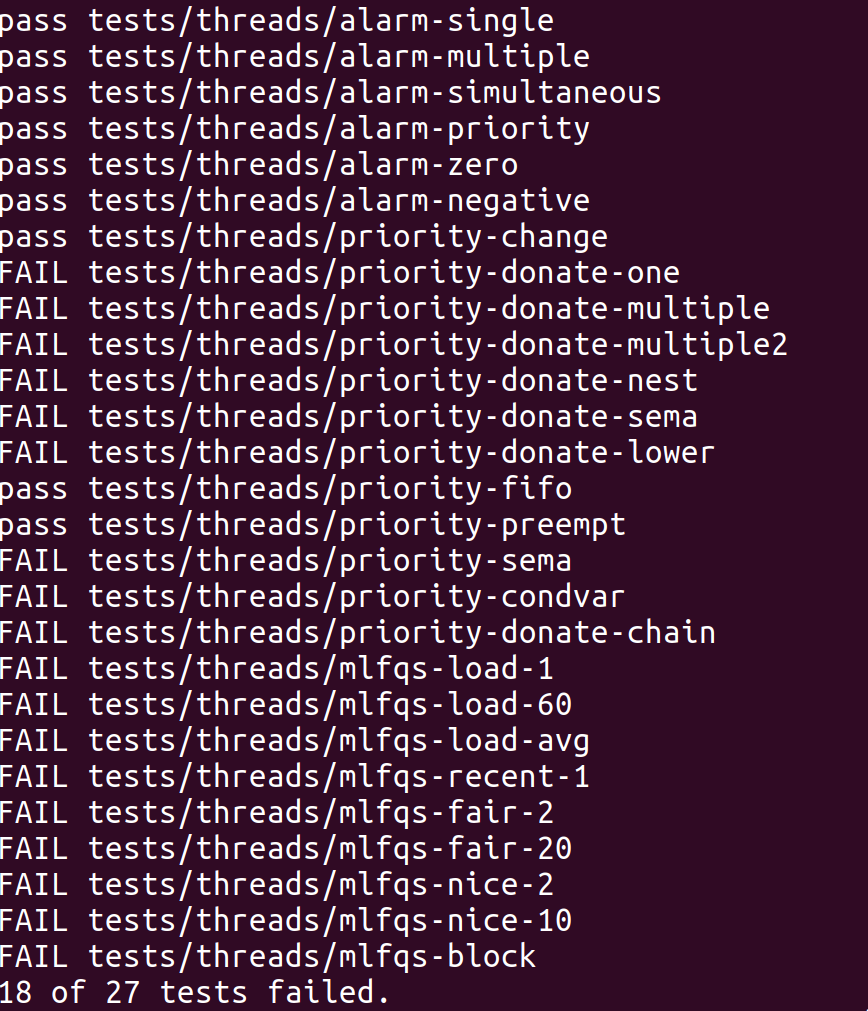
review remaining tests
优先级捐赠:当发现高优先级的任务因为低优先级任务占用资源而阻塞时,就将低优先级任务的优先级提升到等待它所占有的资源的最高优先级任务的优先级。
由priority-donate-one测试代码可知,在一个线程获取一个锁的时候,如果拥有这个锁的线程优先级比自己低就提高它的优先级,然后在这个线程释放掉这个锁之后把原来拥有这个锁的线程改回原来的优先级。
priority-donate-multiple和priority-donate-multiple2是测试多锁情况下优先级逻辑的正确性。释放一个锁的时候,将该锁的拥有者改为该线程被捐赠的第二优先级,若没有其余捐赠者,则恢复原始优先级。那么线程必然需要一个数据结构来记录所有对这个线程有捐赠行为的线程。
priority-donate-nest是一个优先级嵌套问题,重点在于medium请求的锁被low占有,在这个前提下high再去获取medium已拥有的锁,这种情况的优先级提升具有连环效应,就是medium被提升了,此时low线程应该跟着一起提升。需要加一个数据结构,需要获取这个线程请求的锁被哪些线程占有。
priority-donate-sema包含了信号量和锁混合触发,实际上还是信号量在起作用,因为锁是由信号量实现的。
priority-donate-lower测试的逻辑是当修改一个被捐赠的线程优先级的时候的行为正确性。
priority-sema中,信号量V唤醒线程的时候也是先唤醒优先级高的。换句话说,信号量的等待队列是个优先级队列。
priority-condvar同理,condition的waiters队列是个优先级队列。
priority-donate-chain是一个链式优先级捐赠,本质测试的还是多层优先级捐赠逻辑的正确性。需要注意的是一个逻辑:释放掉一个锁之后,如果当前线程不被捐赠即马上改为原来的优先级,抢占式调度。
逻辑总结为:
一个线程获取一个锁的时候,如果拥有这个锁的线程优先级比自己低,就提高它的优先级,即捐赠优先级。如果这个锁还被别的锁锁着,就递归捐赠优先级,在这个线程释放掉这个锁之后恢复未捐赠逻辑下的优先级。
如果一个线程被多个线程捐赠,将当前的优先级设定为捐赠优先级中的最大值。
在对一个线程进行优先级设置的时候,如果这个线程处于被捐赠状态,则对base_priority进行设置。如果设置的优先级大于当前优先级,则改变当前优先级,否则在捐赠状态取消的时候恢复base_priority。
在释放锁对一个锁优先级有改变的时候,应考虑其余被捐赠优先级和当前优先级,优先级嵌套的问题。
将信号量的waiters队列和condition的waiters队列实现为优先级队列。
释放锁的时候,若优先级改变,可以发生抢占。
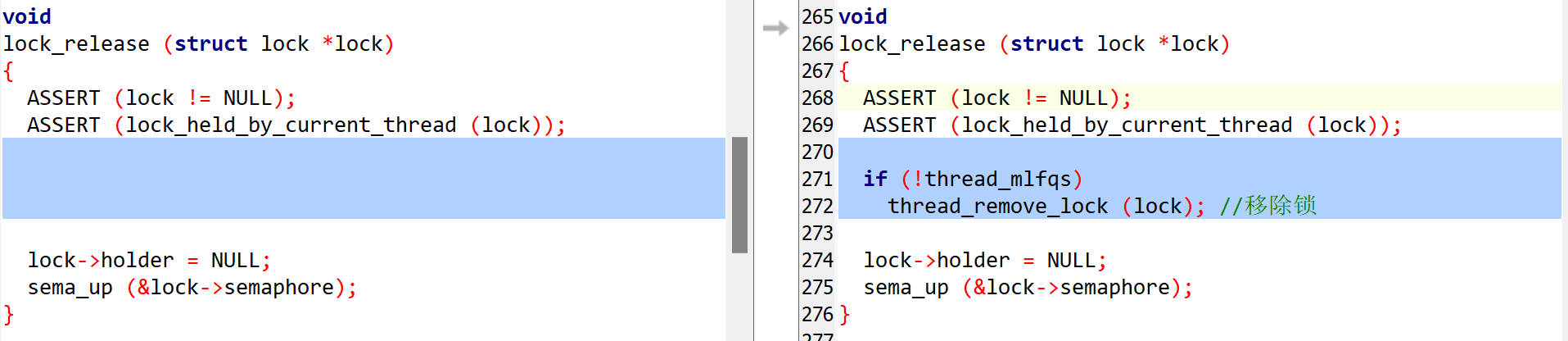
synch.c
在synch.h中的lock结构体中加入成员:
struct list_elem elem; /* List element for priority donation. */ |
锁的获取和释放
void |
比较函数
bool |
bool |
信号量相关

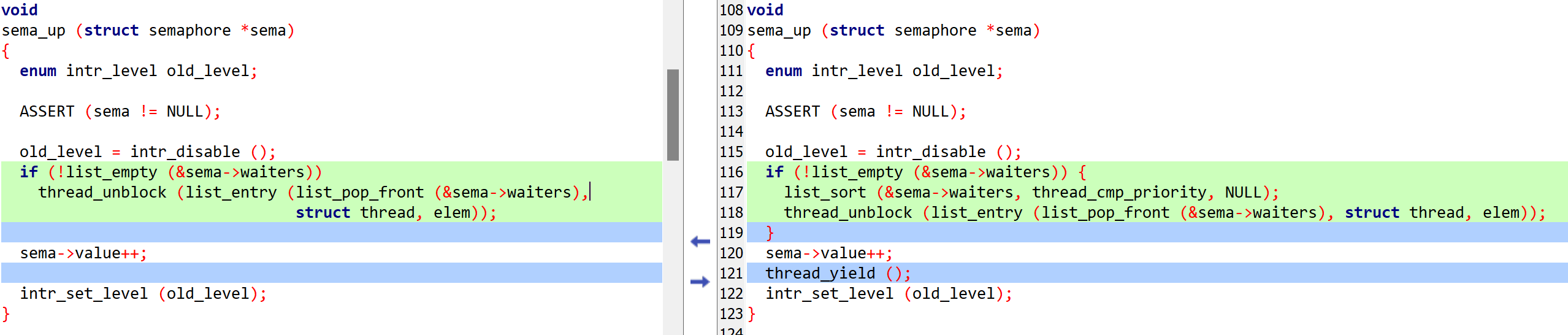
condition_variable相关

thread.c
在thread结构体中加入如下成员:
int base_priority; /* Base priority. */ |
在init_thread中加入如下代码:
t->base_priority = priority; |
thread_set_priority
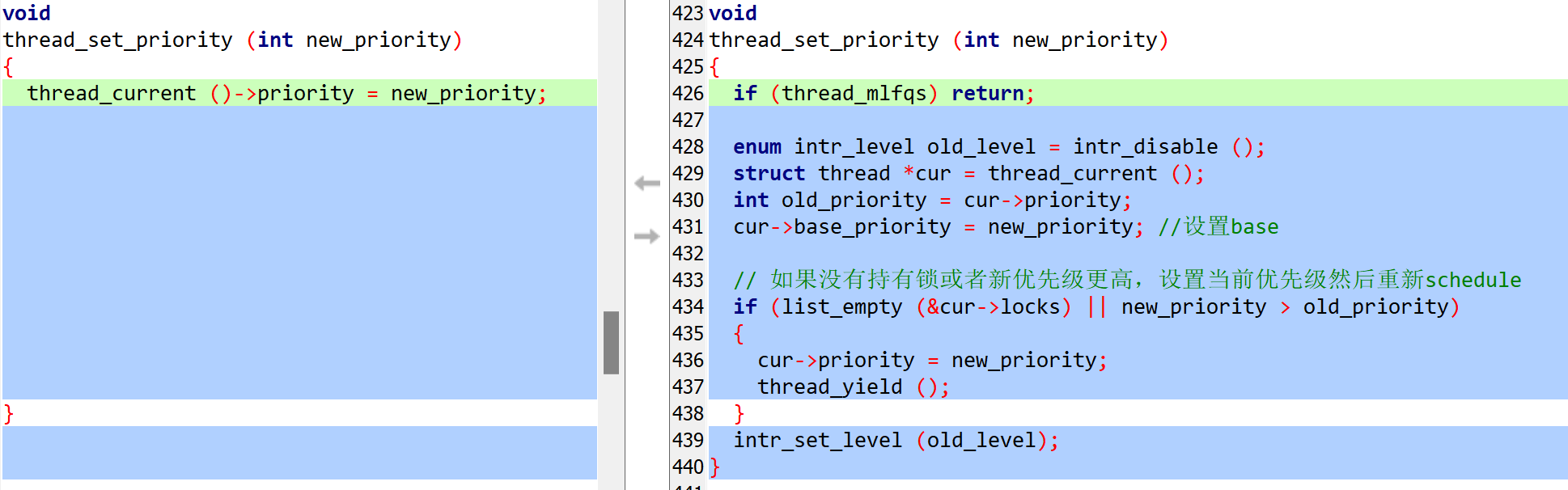
thread_donate_priority
/* Donate current priority to thread t. */ |
thread_hold_the_lock
/* Let thread hold a lock */ |
thread_remove_lock
/* Remove a lock. */ |
thread_update_priority
/* Update priority. */ |
再测试
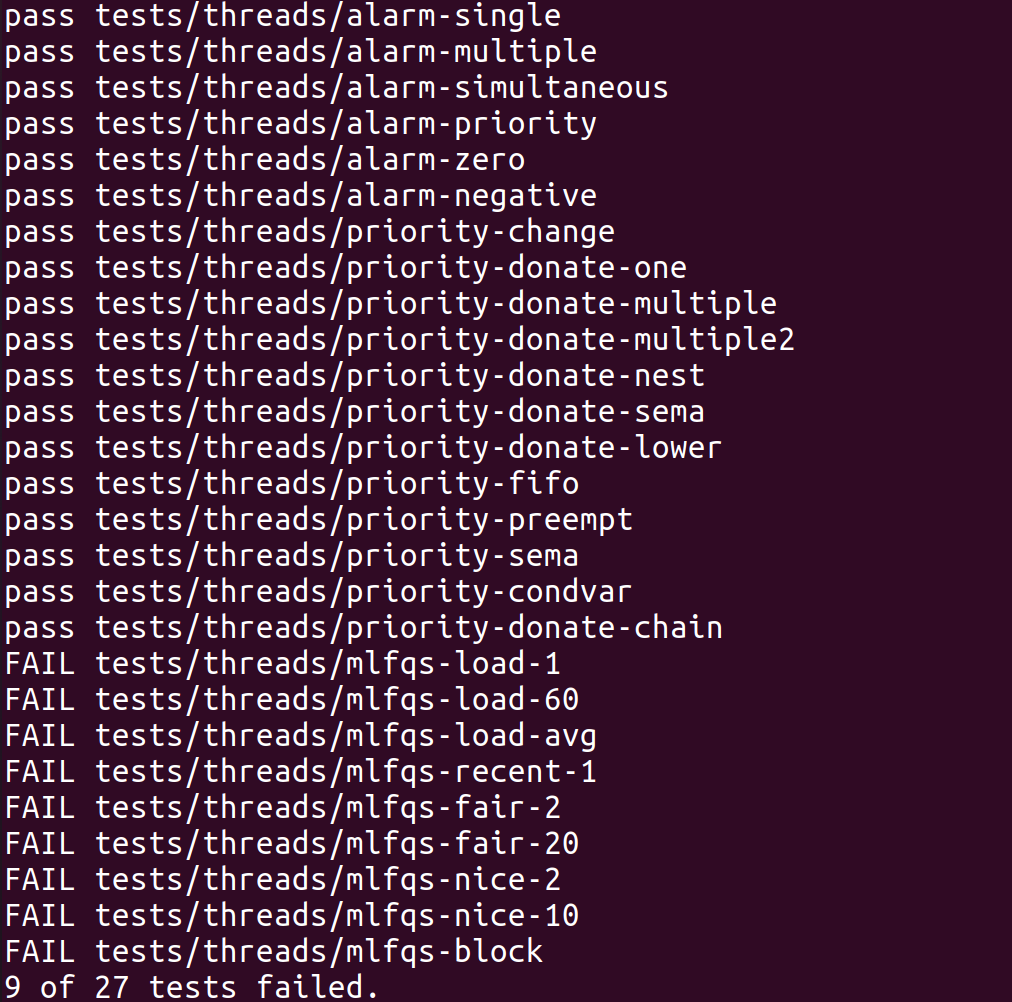
Advanced Scheduler
Implement a multilevel feedback queue scheduler similar to the 4.4BSD scheduler to reduce the average response time for running jobs on your system. See section B. 4.4BSD Scheduler, for detailed requirements.
Like the priority scheduler, the advanced scheduler chooses the thread to run based on priorities. However, the advanced scheduler does not do priority donation. Thus, we recommend that you have the priority scheduler working, except possibly for priority donation, before you start work on the advanced scheduler.
You must write your code to allow us to choose a scheduling algorithm policy at Pintos startup time. By default, the priority scheduler must be active, but we must be able to choose the 4.4BSD scheduler with the -mlfqs kernel option. Passing this option sets thread_mlfqs, declared in threads/thread.h, to true when the options are parsed by parse_options(), which happens early in main().
When the 4.4BSD scheduler is enabled, threads no longer directly control their own priorities. The priority argument to thread_create() should be ignored, as well as any calls to thread_set_priority(), and thread_get_priority() should return the thread’s current priority as set by the scheduler.
计算公式
以下公式总结了实现调度程序所需的计算,但不是调度程序要求的完整描述。
每个线程在其控制下都有一个介于-20和20之间的nice值。每个线程还有一个优先级,介于0(PRI_MIN)到63(PRI_MAX)之间,每四个tick使用以下公式重新计算一次:
recent_cpu测量线程“最近“收到的CPU数。在每个计时器tick中,正在运行的线程的recent_cpu增加1。每个线程的recent_cpu以这种方式每秒更新一次:
load_avg估计过去一分钟就绪的平均线程数,它在启动时初始化为0,并每秒重新计算一次,如下所示:
其中ready_threads是正在运行或就绪的线程数(不包括空闲线程)。
浮点数运算规则
The following table summarizes how fixed-point arithmetic operations can be implemented in C. In the table, x and y are fixed-point numbers, n is an integer, fixed-point numbers are in signed p.q format where p + q = 31, and f is 1 << q :
| Description | Expression |
|---|---|
Convert n to fixed point: |
n * f |
Convert x to integer (rounding toward zero): |
x / f |
Convert x to integer (rounding to nearest): |
(x + f / 2) / f if x >= 0, (x - f / 2) / f if x <= 0. |
Add x and y: |
x + y |
Subtract y from x: |
x - y |
Add x and n: |
x + n * f |
Subtract n from x: |
x - n * f |
Multiply x by y: |
((int64_t) x) * y / f |
Multiply x by n: |
x * n |
Divide x by y: |
((int64_t) x) * f / y |
Divide x by n: |
x / n |
devices/timer.c
在timer_interrupt中,每TIMER_FREQ时间(系统默认值是100)更新一次系统load_avg和所有线程的recent_cpu;每4个ticks更新一次线程优先级;每个timer_tick,running线程的recent_cpu递增。本质上还是优先级调度,保留之前写的优先级调度代码,在优先级捐赠相关函数中加thread_mlfqs判断。在timer_interrupt函数中加入如下代码。
if (thread_mlfqs) |
threads/thread.c
在thread结构体中加入int成员nice和recent_cpu。然后在init_thread中进行初始化。
t->nice = 0; |
定义全局变量static int load_avg;,然后在thread_init中将其初始化load_avg = FP_CONST (0);。
浮点数运算
在代码靠前位置加入浮点数运算相关的定义。
/* 浮点运算相关 */ |
这里用低16位数作为浮点数的小数部分,无论什么运算一定要维持整数部分从第17位开始。
recent_cpu & load_avg
timer_interrupt中涉及的三个函数如下,分别是递增recent_cpu、更新优先级、更新load_avg及recent_cpu。计算逻辑即参考公式。
/* Update priority. */ |
然后完善头文件中已经写好的几个函数原型。
/* Sets the current thread's nice value to NICE. */ |
测试
测试的时候,发现mlfqs测试的默认时限为60s,测试时很容易因为超时而终止,暂不清楚这与模拟器是qemu/bochs是否有关。以运行mlfqs-load-60为例,需要计算180s左右的load。Timer在整个程序执行过程中经历了18827个tick,约为188s。
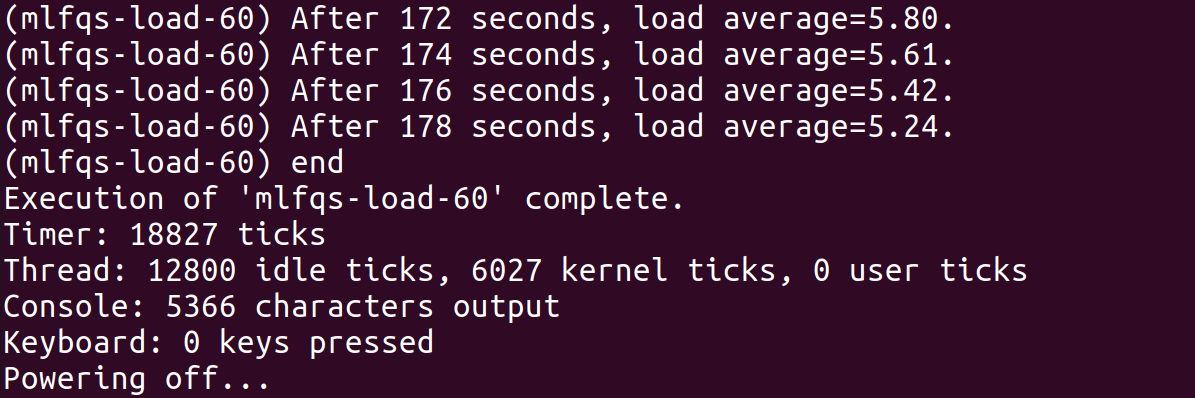
此时,修改src/tests/threads/Make.tests文件末尾的TIMEOUT参数,把默认值60改掉(如改为200)后,测试可以通过。

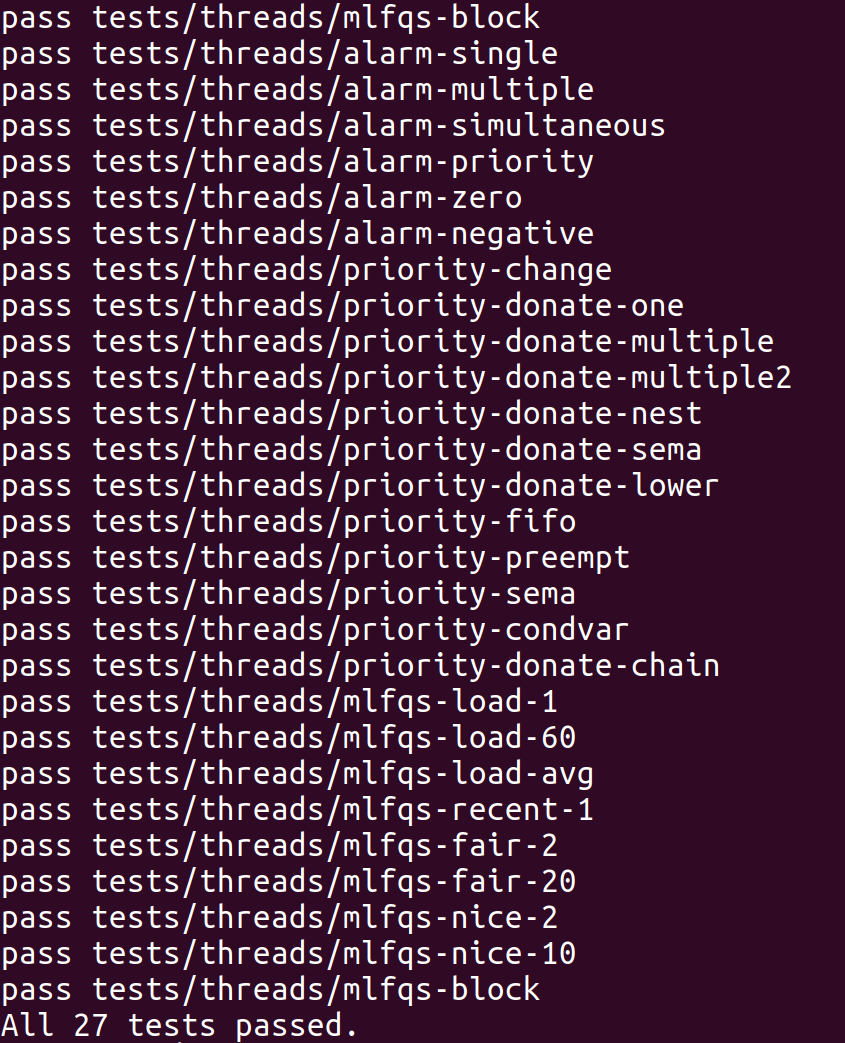
最终测试结果如下:
 alipay
alipay