CS149 - Programming Assignments 2
概述
课程链接https://gfxcourses.stanford.edu/cs149/fall21
项目链接https://github.com/stanford-cs149/asst2
参考链接https://github.com/chenxfeng/asst2
我的源码https://github.com/lfalive/asst2
实验环境
git clone https://github.com/stanford-cs149/asst2.git |
任务
修改完善以下文件。
- part_a/task_sys.cpp
- part_a/task_sys.h
- part_b/task_sys.cpp
- part_b/task_sys.h
测试
在part_a或part_b目录执行make编译后,可以运行单个任务:
./runtasks -n 8 mandelbrot_chunked |
也可以执行所有测试:
python ../tests/run_test_harness.py |
可选择部分测试运行,可修改运行线程数,使用-h参数查看帮助。
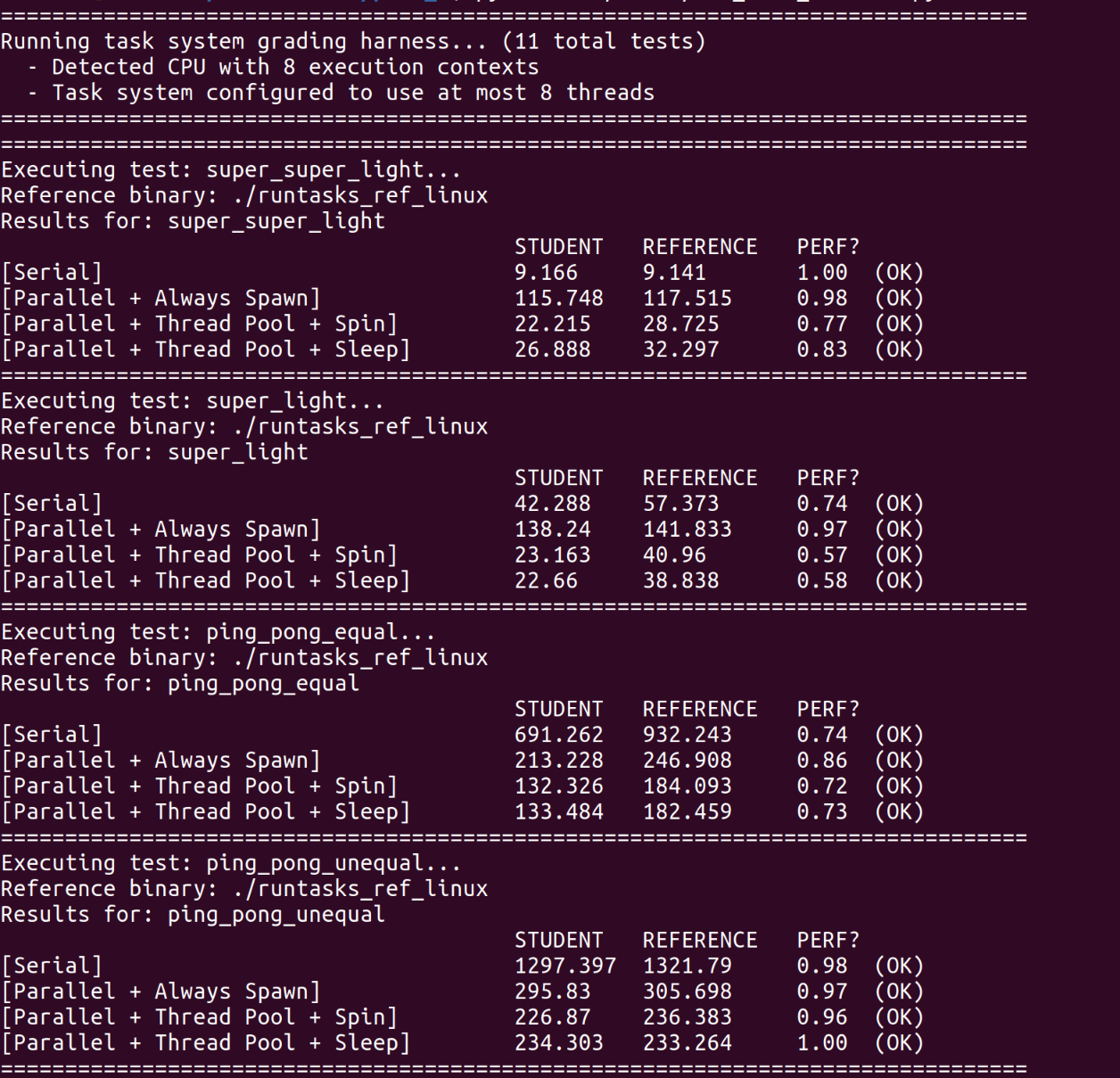
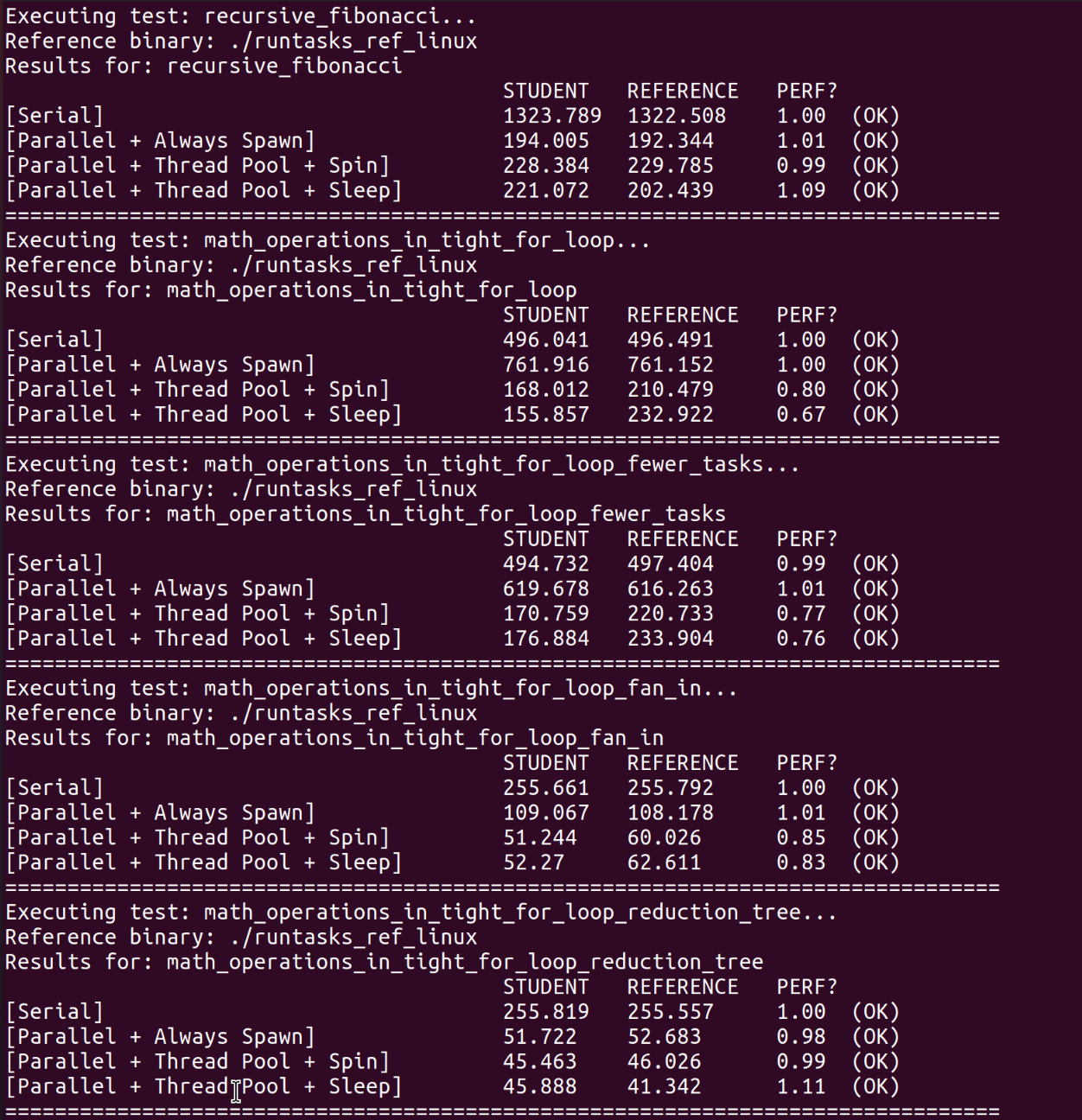
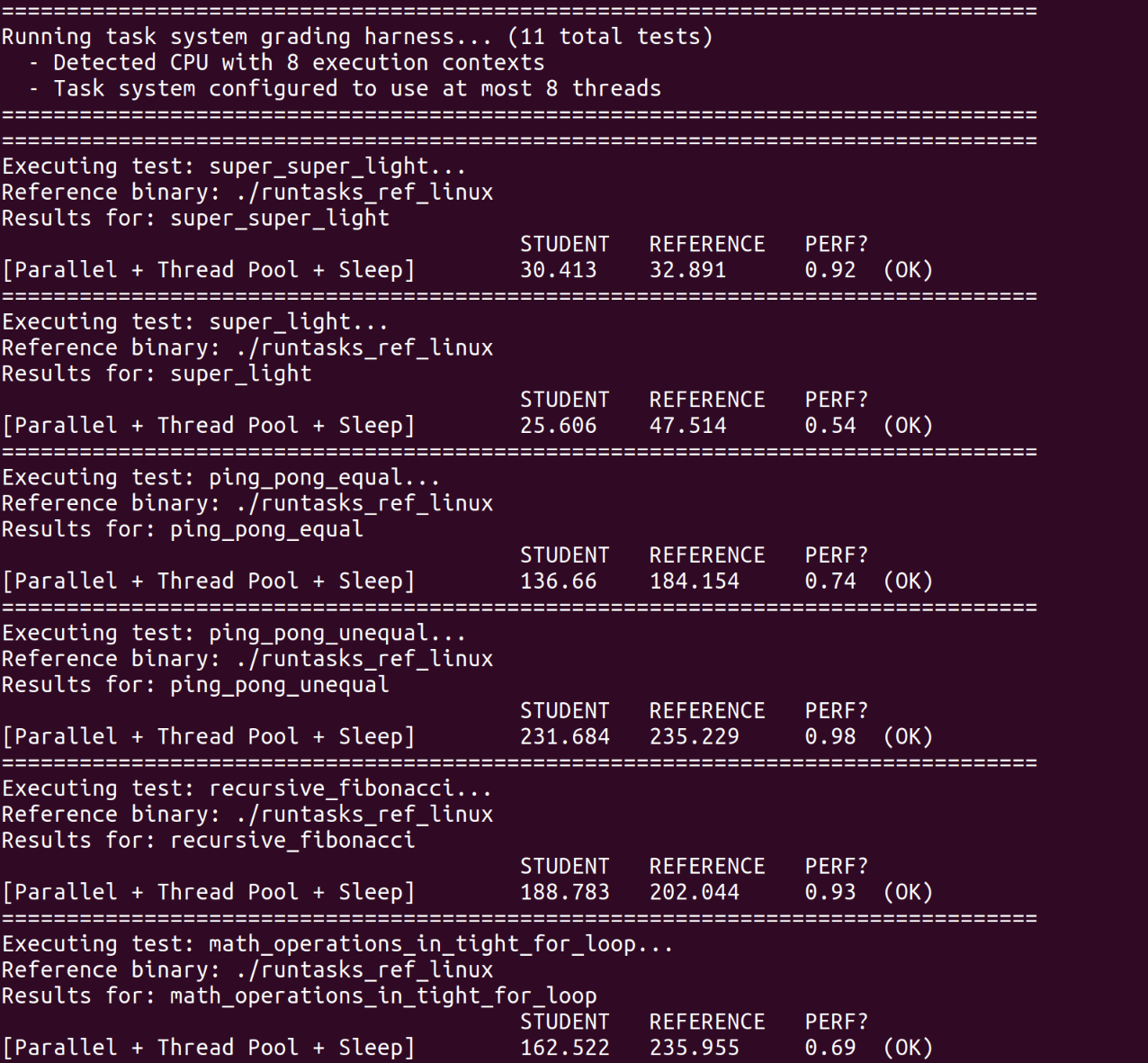
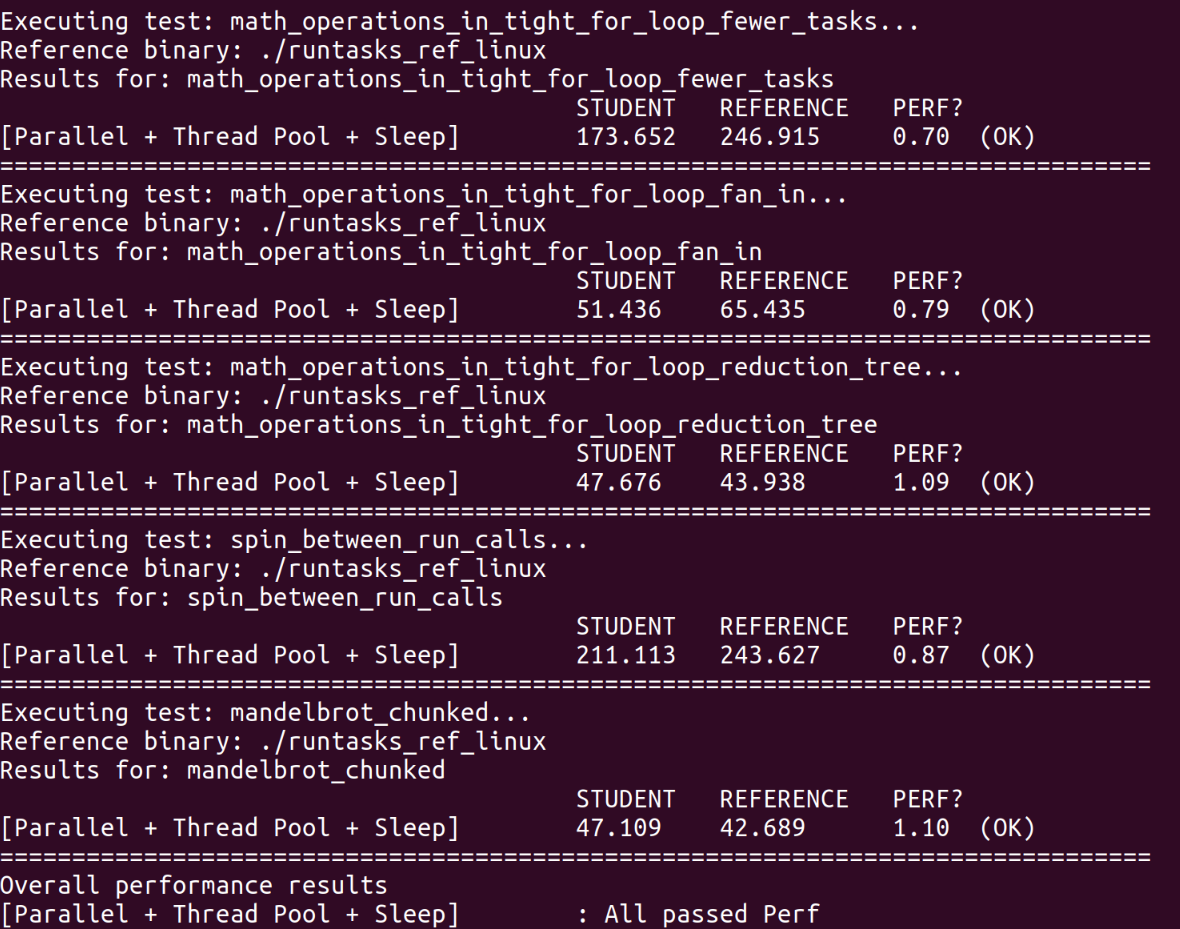
测试输出中的PERF是实际运行时间与参考解决方案的运行时间的比率。小于1的值表明我们的任务系统实现比参考实现更快。
part_a
Synchronous Bulk Task Launch
Task System Parallel Spawn
在分配这一步中,将扩展启动程序代码,以并行执行批量任务启动。
创建额外的线程控制程序来执行批量任务启动的工作。TaskSystem的构造函数提供了一个参数num_threads,它是可以用来运行任务的最大工作线程数。
本着”先做最简单的事情”的精神,建议在run()开始时生成工作线程,并在run()返回之前join这些线程。这将是一个正确的实现,但它会因频繁创建线程而产生大量开销。
如何将任务分配给工作线程?应该考虑线程静态或动态的任务分配吗?
是否有共享变量(任务执行系统的内部状态)需要防止多线程同时访问?可能需要查看C++同步教程,了解C++标准库中的同步原语。
solution
使用原子操作,定义一个atomic_int表示taskId,循环所有task,分配给不同线程运行。原子操作保证了同一个task不会被执行多次。
TaskSystemParallelSpawn::TaskSystemParallelSpawn(int num_threads) : ITaskSystem(num_threads) { |
运行测试,all passed。
Task System Parallel Thread Pool Spinning
每次调用run() 新建和销毁线程的时候,当任务的计算成本很低时,新建和销毁线程的开销尤其明显。此时,建议转移到“线程池”实现,任务执行系统会预先创建所有工作线程(例如在TaskSystem构造期间,或在第一次调用run()时)。
- 我们将工作线程设计为循环,始终检查是否还有更多工作要执行(进入while循环直到条件为真的线程通常称为“旋转”)。工作线程如何确定有工作要做?
- 现在确保
run()实现所需的同步行为并非易事。需要如何更改执行run()才能确定批量任务启动中的所有任务都已完成?
solution
在头文件中加入以下:
std::vector<std::thread> threads; |
threads是系统中的所有线程,mutex和queue实现一个互斥的任务队列,队列元素是taskId。原子变量taskRemained表示剩余任务数。剩余任务清零时run()结束。
构造函数和析构函数中设置exitFlag,以及创建和销毁线程。线程函数func()中,循环取出任务队列中的任务,如果队列为空,就继续循环。成功执行任务后,原子地使taskRemained递减。run()中,互斥地将所有taskId放入任务队列即可。
TaskSystemParallelThreadPoolSpinning::TaskSystemParallelThreadPoolSpinning(int num_threads) : ITaskSystem(num_threads) { |
运行测试,all passed。
Task System Parallel Thread Pool Sleeping
第2步实现的缺点之一是线程在“旋转”等待某事执行时会利用CPU内核的资源。例如,工作线程可能会循环等待新任务的到达。作为另一个示例,主线程可能会循环等待工作线程完成所有任务,以便它可以结束run()。 这可能会损害性能,因为CPU资源用于运行这些线程,即使这些线程没有做有用的工作。
在这部分作业中,希望通过让线程休眠直到满足它们等待的条件来提高任务系统的效率。
- 您的实现可以选择使用条件变量来实现此行为。条件变量是一种同步原语,它使线程在等待条件存在时能够休眠(并且不占用 CPU 处理资源)。其他线程“发出信号”等待线程唤醒以查看它们等待的条件是否已满足。例如,如果没有工作要做,您的工作线程可能会进入睡眠状态(因此它们不会从试图做有用工作的线程中占用 CPU 资源)。作为另一个示例,调用的主应用程序线程
run()可能希望在等待工作线程完成批量任务启动中的所有任务时休眠。(否则,旋转的主线程会占用工作线程的 CPU 资源!)请参阅C++ 同步教程,了解有关 C++ 中条件变量的更多信息。 - 在这部分作业中的实现可能需要考虑棘手的竞争条件,需要考虑许多可能的线程交错行为。
solution
头文件:
private: |
counterLock和counterCond是在task完成后唤醒主线程。queueMutex和taskQueue组成互斥队列,配合queueCond,可以使线程空闲时休眠,不占用资源。
TaskSystemParallelThreadPoolSleeping::TaskSystemParallelThreadPoolSleeping(int |
构造函数中设定exitFlag,创建线程执行func。
func中,线程执行一个大循环。然后进小循环,休眠等待唤醒。被唤醒后就尝试获取任务队列的锁。如果有退出标志,直接结束线程。如果队列为空,继续小循环。否则就取出队头任务,释放锁,然后开始执行任务。执行任务结束后taskRemained递减,如果还剩余任务,就唤醒工作线程,否则唤醒主线程的counterCond,检查是否可以结束run。
run中,必要的初始化后,就开始互斥地将所有任务放进队列,然后唤醒所有工作线程开始工作。任务入队完成后,就开始休眠等待counterCond信号了。
析构函数中,此时所有工作线程应该都是休眠状态,那么就先设定退出标志,再唤醒所有线程,最后等待所有工作线程结束即可。
测试
All passed Perf。

part_b
扩展part_a任务系统实现,以支持异步启动任务,这些任务可能依赖于以前的任务。这些任务间的依赖关系创建了任务执行时必须遵守的调度约束。
首先,使用runAsyncWithDeps()创建的任务由任务系统与调用线程异步执行。这意味着runAsyncWithDeps()应该立即返回,即使任务尚未完成执行。该方法返回与此批量任务启动关联的唯一标识符。
与之前所有批量任务启动相关联的任务完成后,sync()返回。
part_b支持显式的依赖关系,runAsyncWithDeps()的第三个参数尤为关键:TaskID标识符的向量。它必须引用以前使用的批量任务启动来 runAsyncWithDeps()。此向量指定当前批量任务启动中的任务所依赖的先前任务。因此,在依赖向量中给定的启动中的所有任务完成之前,无法开始执行当前批量任务启动中的任何任务!很明显,任务调度图是一个有向无环图(DAG)。
正确实现TaskSystemParallelThreadPoolSleeping::runAsyncWithDeps()和TaskSystemParallelThreadPoolSleeping::sync(),不需要实现part_b中其他TaskSystem。
- 考虑以下行为可能会有所帮助:
runAsyncWithDeps()一旦将要工作的记录在队列中,就可以返回给调用者。 - 在您的实现中拥有两个数据结构会很有帮助:一个表示已通过调用添加到系统中的任务的结构
runAsyncWithDeps(),但尚未准备好执行,因为它们依赖于仍在运行的任务(这些任务正在“等待”其他任务完成)。一个未等待任何先前任务完成的“任务就绪队列”,并且可以在工作线程可用于处理它们时安全运行。 - 在生成唯一的任务启动 ID 时,不必担心整数溢出。我们不会通过超过2^31个批量任务启动来打击您的任务系统。
- 您可以假设所有程序都只会调用
run()或仅runAsyncWithDeps()。请注意,此假设意味着您可以实现run()使用适当的调用runAsyncWithDeps()和sync()。
修改run_test_harness.py
因为part_b只需要实现Task System Parallel Thread Pool Sleeping,所以在测试时也只需要测试这个系统。

修改test/run_test_harness.py文件,注释掉前三项即可。
solution
乍一看很复杂,其实在part_a的Task System Parallel Thread Pool Sleeping上做出一些改动即可。新增了优先队列,来维护任务组之间的顺序,保证队首任务组是不依赖其他任务组的或者依赖最少的。还考虑过拓扑排序什么的,有了优先队列,就省事多了。最后效果不错,全pass了。
头文件
struct TaskGroup { |
引入两个结构体。TaskGroup是每次调用runAsyncWithDeps时会创建的对象,表示一个任务组,包含编号groupId,runnable,总task数numTotalTasks,剩余task数taskRemained(原子变量),依赖任务组集合depending。同时,还重载了小于运算符,这样就能在优先队列中直接按照依赖任务组数从少到多维护。
RunnableTask是放入互斥任务队列taskQueue中的元素,成员是taskId和指向所属TaskGroup对象的指针。
std::vector<std::thread> threads; |
相较于part_a,Task System Parallel Thread Pool Sleeping类中新增了一些成员。taskGroupSet中包含所有TaskGroup对象,优先队列taskGroupQueue是解决问题的核心,finishFlag标记是否所有task都已经完成,numGroup表示总group数。
run()
void TaskSystemParallelThreadPoolSleeping::run(IRunnable *runnable, int num_total_tasks) { |
如果调用的是run(),就新建一个没有任何依赖的的任务组,然后调用sync()。
构造与析构
TaskSystemParallelThreadPoolSleeping::TaskSystemParallelThreadPoolSleeping(int num_threads) : ITaskSystem(num_threads) { |
和part_a相同,只是多了numGroup的初始化。
runAsyncWithDeps()
TaskID TaskSystemParallelThreadPoolSleeping::runAsyncWithDeps(IRunnable *runnable, int num_total_tasks, |
很清晰,构造一个TaskGroup对象,然后将其分别放入优先队列和集合,最后group数递增。
func()
void TaskSystemParallelThreadPoolSleeping::func() { |
和part_a不同的是,取出RunnableTask对象后,还要找到所述TaskGroup对象,然后再调用runTask()。执行完成后,所属group剩余任务数递减。如果剩余任务数不大于0,则表示该任务组的所有任务已完成,循环所有TaskGroup,在depending集合中删除当前任务组。这是,优先队列会自动维护。
sync()
void TaskSystemParallelThreadPoolSleeping::sync() { |
只要任务组队列不为空,就循环检查队首元素是否已经不依赖任何其他任务组,如果是,就循环生成numTotalTasks个RunnableTask,互斥地放入任务队列中去执行。同样的,每放入一组任务,都唤醒等待的工作线程去获取任务。
每次有任务组完成,都会发送counterCond信号,sync()中等待此信号。收到信号后,如果所有任务组都已经完成,就返回函数。
测试
 alipay
alipay