内存分配器JeMalloc学习
简介
https://github.com/jemalloc/jemalloc
JeMalloc是一款内存分配器,与其它内存分配器相比,它最大的优势在于多线程情况下的高性能以及内存碎片的减少。
论文(2006)
http://people.freebsd.org/~jasone/jemalloc/bsdcan2006/jemalloc.pdf
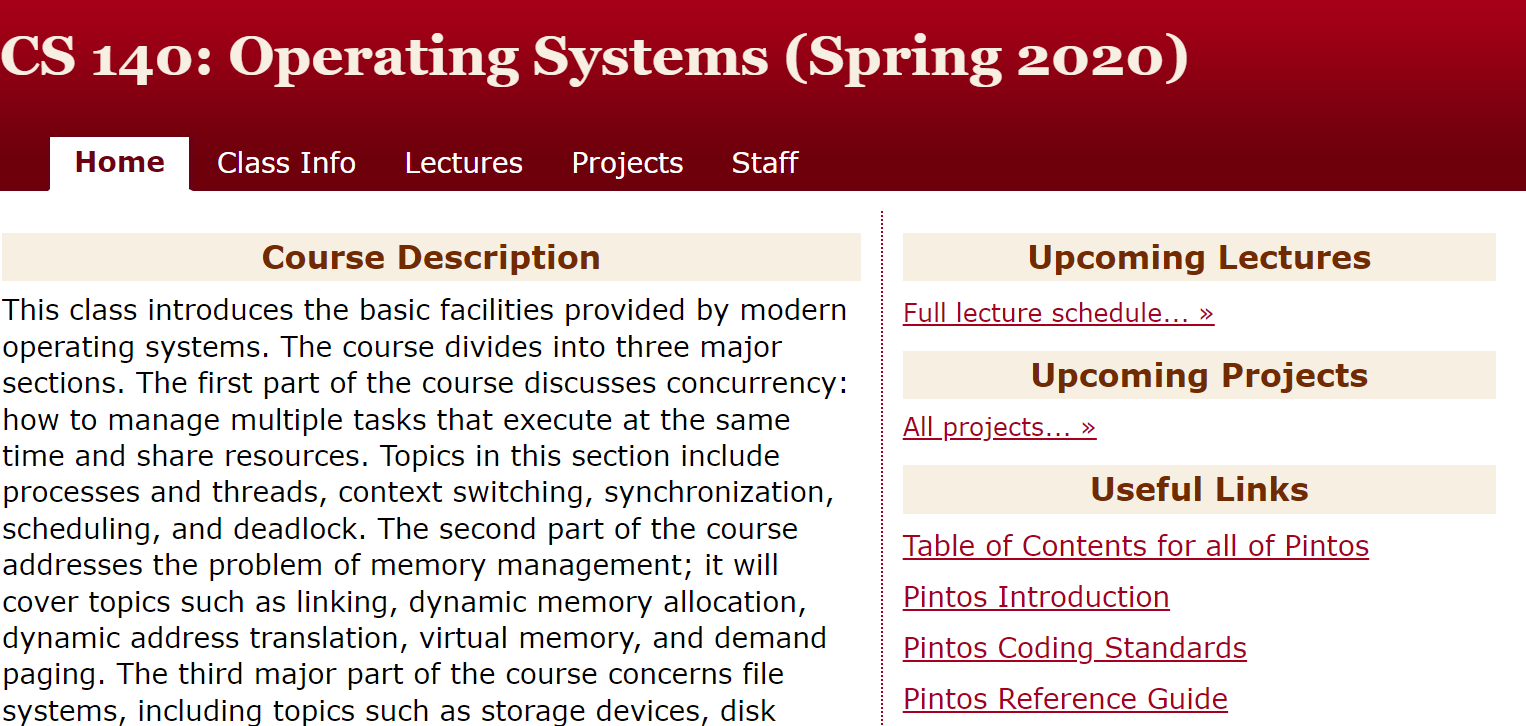
每个应用程序在运行时配置为具有固定数量的竞技场(Arena)。默认情况下,Arena的数量取决于处理器的数量:
- 单处理器:所有分配使用一个Arena。使用多个Arena没有意义。
- 多处理器:使用四倍于处理器数量的Arena。通过将线程分配给一组Arena,单个Arena被同时使用的概率会降低。
线程第一次分配或释放内存时,它被分配到一个Arena。Arena是以循环方式选择的,这样可以保证分配给Arena的线程数量大致相同。线程仍然可以在特定的Arena上相互竞争,但平均而言,不可能比循环分配做得更好。动态重新平衡可能会减少竞争,但必要的记录成本很高。
线程本地存储(TLS)对于有效实现Arena的循环分配非常重要,因为每个线程的Arena分配都需要存储在某个地方。
通过sbrk或mmap从内核请求的所有内存都以“块(chunk)”的大小的倍数进行管理,这样chunk的基址总是chunk大小的倍数。chunk的这种对齐方式允许对与分配相关联的chunk进行恒定时间的计算。默认情况下,chunk大小为2MB,chunk大小始终相同,并且从chunk对齐的地址开始。Arena将chunk分割进行更小的分配,但巨大的分配直接由一个或多个连续chunk支持。
分配的大小分为三大类:small、large和huge。所有分配请求均向上舍入到最近的大小类别边界。huge的分配的空间比chunk的一半还大,并由专用块直接支持。关于huge分配的元数据,存储在一棵红黑树中。由于大多数应用程序创建的huge分配很少(如果有的话),因此使用树不会出现可伸缩性问题。
对于small和large的分配,使用Binary Buddy算法将chunk分割成pages运行。关于运行状态的信息存储在每个chunk的开头,作为页面映射。large分配的空间大于pages的一半,但不大于块的一半。
小型分配分为三个子类别:tiny、quantum-spaced和sub-page。在实践中,大小为2的次幂的空间对于tiny的分配是有效的。量子大小通常为16字节。下图显示了所有分配大小的大小类。
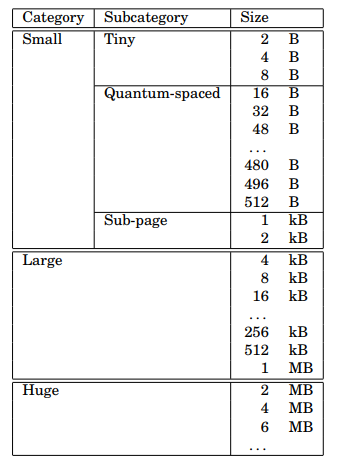
如果取消quantum-spaced类,没有用于小型分配的子类,将更简单。然而,大多数应用程序主要分配小于512字节的对象,各类之间的量子间距大大减少了平均内部碎片。较多的大小类可能会导致外部碎片增加,但在实践中,减少的内部碎片通常会抵消增加的外部碎片。
small的分配是分开的,在每次运行开始时存储区域位图(BitMap),与其他方法相比,该方法有几个优点:
位图可以快速扫描第一个空闲区域,这允许对正在使用的区域进行紧密打包。
分配器数据和应用程序数据是分开的。这降低了应用程序损坏分配器数据的可能性。这还可能增加应用程序数据的局部性,因为分配器数据不会与应用程序数据混合。
微小的区域很容易得到支持。
为了限制外部碎片,除了最小类之外,所有类都使用多页运行。因此,对于最大的小型类(通常为2kb区域),外部碎片限制在大约3%。
在任何给定的时间内,每个尺寸类最多有一次“当前运行”。“当前运行”将保持当前状态,直到完全填满或完全清空。运行状态按照四分位数进行分类,QINIT类别的run永远不会被破坏。为了销毁某个运行,必须首先将其提升到更高的fullness等级。
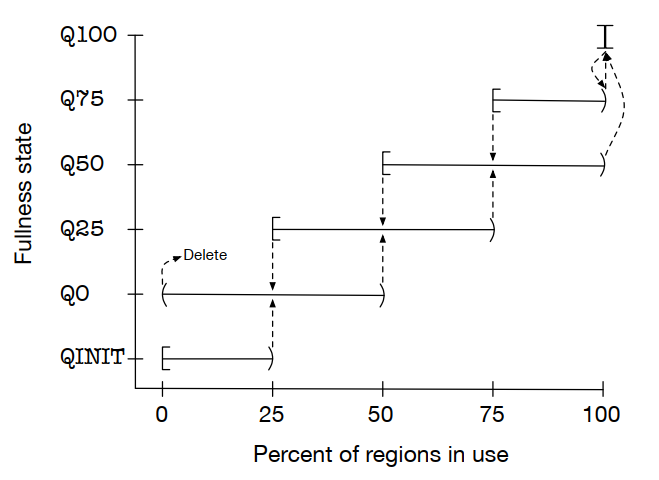
fullness类别还提供了一种从非完整运行中选择新“当前运行”的机制。偏好顺序是:Q50、Q25、Q0,然后是Q75。常规地这样选择会导致“当前运行”的快速切换。
对内存分配器进行详尽的基准测试是不可行的,基准测试结果在任何意义上都不应被解释为肯定的。分配器性能对应用程序分配模式非常敏感,基准测试者可以心血来潮,构建微基准,以有利或不利的角度显示本文测试的三个分配器中的任何一个。作者尽了一切努力避免这种结果的扭曲,但他的客观性不应该被我们读者所假定。基准测试应该足以让读者相信至少以下几点:
jemalloc适用于在多处理器系统上运行的多线程程序。
在单线程程序上的运行时间和内存使用方面,jemalloc表现出与phkmalloc和dlmalloc相似的性能。
事实上,jemalloc在所介绍的基准测试中表现得非常好,作者认为,没有任何理由怀疑jemalloc在除了精心制作的微基准测试之外的任何方面会比phkmalloc或dlmalloc表现得差得多。
这些基准测试都不是为测量内存压力下的性能而设计的。本文没有包括,主要是因为phkmalloc在内存压力下表现良好,而jemalloc使用了足够相似的算法,因此应该表现出相似的性能。碎片化很难分析,因为它主要是一个定性问题,标准工具只提供定量指标。
开发jemalloc时经常遇到的一个问题是,即使是看似无害的附加功能,例如维护每个Arena的总分配内存计数器,也会导致性能下降。分配器设计之初的特性比最终的多得多。
分配器的设计和实现的一部分吸引力在于,对于所有可能的分配模式,没有哪个分配器是优越的,所以在新软件引入新的分配模式时,总是需要进行微调。
手册(jemalloc 5.2.1)
Standard API
void *malloc(size_t size);
分配大小为size字节的未初始化内存。分配的空间被适当地对齐,以便于存储任何类型的对象。
void *calloc(size_t number, size_t size);
为number个对象分配空间,每个对象的长度为size字节。结果与使用number*size参数调用malloc()相同,只是分配的内存被显式初始化为0字节。
int posix_memalign(void **ptr, size_t alignment, size_t size);
分配size字节的内存,使分配的基址是alignment的倍数,并以ptr指向的值返回分配。请求的alignment必须是2的幂,至少与sizeof(void *)大小相同。
void *aligned_alloc(size_t alignment, size_t size);
分配size字节的内存,使分配的基址是alignment的倍数。请求的alignment必须是2的幂。如果size不是alignment的整数倍,则行为未定义。
void *realloc(void *ptr, size_t size);
函数将ptr引用的先前分配内存的大小更改为size字节。内存的内容在新旧大小中以较小者为准。如果新大小更大,则新分配的内存部分的内容未定义。成功后,ptr引用的内存将被释放,并返回指向新分配内存的指针。请注意,realloc()可能会移动内存分配,从而产生与ptr不同的返回值。如果ptr为NULL,realloc()函数在指定大小下的行为与malloc()相同。
void free(void *ptr);
使ptr引用的已分配内存可用于将来的分配。如果ptr为NULL,则不会发生任何操作。
Non-standard API
void *mallocx(size_t size, int flags);
分配至少size字节的内存,并返回一个指向分配基址的指针。如果大小为0,则行为未定义。
void *rallocx(void *ptr, size_t size, int flags);
将ptr处的分配调整为至少size字节,并返回一个指向最终分配的基址的指针,该地址可能已从其原始位置移动,也可能未从其原始位置移动。如果大小为0,则行为未定义。
size_t xallocx(void *ptr, size_t size, size_t extra, int flags);
将ptr处的分配调整为至少size字节,并返回分配的实际大小。如果extra为非零,则会尝试调整为至少size + extra字节,且无法分配额外字节并不会导致分配失败。如果size为0,或者size + extra > SIZE_T_MAX,则行为未定义。
size_t sallocx(void *ptr, int flags);
返回ptr处分配的实际大小。
void dallocx(void *ptr, int flags);
使ptr引用的内存可用于将来的分配。
void sdallocx(void *ptr, size_t size, int flags);
sdallocx()函数是dallocx()的一个扩展,带有一个size参数,允许调用方传递分配大小。最小有效输入大小是分配的原始请求大小,最大有效输入大小是nallocx()或sallocx()返回的相应值。
size_t nallocx(size_t size, int flags);
nallocx()函数不分配内存,但它执行与mallocx()函数相同的大小计算,并返回等效mallocx()函数调用产生的分配的实际大小,如果输入超过支持的最大大小类或对齐,则返回0。如果大小为0,则行为未定义。
以上mallocx() , rallocx() ,xallocx() , sallocx() ,dallocx() , sdallocx(),和nallocx()都有flags可用于指定选项的参数。使用位或( |)指定一个或多个参数:
MALLOCX_LG_ALIGN(la)对齐内存分配,使其从一个地址开始,该地址是
(1 << la)的倍数。此宏不验证la在有效范围内。MALLOCX_ALIGN(a)对齐内存分配,使其从一个地址开始,该地址是
a的倍数,其中a是2的幂。此宏不验证a是2的幂。MALLOCX_ZERO初始化新分配的内存以包含0字节。在不断增长的重新分配情况下,重新分配之前的实际大小定义了未接触字节和初始化为包含0字节的字节之间的边界。如果此宏不存在,则新分配的内存将取消初始化。
MALLOCX_TCACHE(tc)使用标识符
tc指定特定线程缓存(tcache)。此宏不验证tc指定的标识符有效。MALLOCX_TCACHE_NONE不要使用特定线程缓存(tcache)。除非使用了
MALLOCX_TCACHE(tc),不然在许多情况下将使用自动管理的tcache。此宏不能作为参数与MALLOCX_TCACHE(tc)用于同一个flags。MALLOCX_ARENA(a)使用索引
a指定的Arena。此宏对指定Arena以外的Arena分配区域无效。此宏不验证索引a指定的Arena在有效范围内。
int mallctl(const char *name, void *oldp, size_t *oldlenp, void *newp, size_t newlen);
mallctl()函数提供了一个通用接口,设置可修改的参数和触发操作。name参数指定树结构命名空间中的位置。要读取一个值,通过oldp传递一个指针,该指针所指向空间有足够的空间来容纳该值,并通过oldlenp传递一个指向其长度的指针;否则传递NULL和NULL。同样,要写一个值,通过newp传递一个指向该值的指针,并通过newlen传递其长度;否则传递NULL和0。
int mallctlnametomib(const char *name, size_t *mibp, size_t *miblenp);
int mallctlbymib(const size_t *mib, size_t miblen, void *oldp, size_t *oldlenp, void *newp, size_t newlen);
mallctlnametomib()提供了一种方法,将name转换为“管理信息库”(MIB),可以重复传递给mallctlbymib(),避免重复查询命名空间相同部分。从mallctlnametomib()成功返回后,mibps是一个包含*miblenp个整数的数组,其中*miblenp是name中的组件数和*miblenp的输入值中的较小者。因此,可以传递小于组件数量的*miblenp,这会产生一个部分MIB,可以用作构建完整MIB的基础。因此,构建如下代码是合理的:
unsigned nbins, i; |
void malloc_stats_print(void(*write_cb)(void *, const char *), void *cbopaque, const char *opts);
写入摘要统计信息。统计数据以人类可读的形式呈现,除非opts字符串中指定了“J”字符,在这种情况下,统计数据以JSON格式呈现。此函数可以重复调用。通过在opts字符串中指定“g”作为字符,可以忽略在执行过程中从不更改的一般信息。请注意,malloc_stats_print()在内部使用mallctl*()函数,因此如果多个线程同时使用这些函数,则可能会报告不一致的统计信息。如果配置过程中指定了--enable stats参数,则可以指定定“m”、“d”和“a”来分别忽略合并的Arena、销毁合并的Arena和打印每个Arena的统计信息;可以指定“b”和“l”来分别忽略bins和large对象的每大小类别统计信息;可以指定“x”来省略所有互斥统计信息;“e”可用于省略范围统计信息。无法识别的字符将被默默忽略。请注意,线程缓存可能会阻止某些统计信息完全更新,因为合并跟踪线程缓存操作的计数器时需要额外的锁。
源码(5.2.1)
参考
https://blog.dbplayer.org/jemalloc-note/
https://uncp.github.io/JeMalloc/
重要特性
- chunk这一概念被替换成了extent
- dirty page的decay变成了两阶段,dirty -> muzzy -> retained(基于衰变的清理)
- huge class这一概念不再存在
- 红黑树不再使用,取而代之的是pairing heap
基本概念
extent
头文件include/jemalloc/internal/extent*.h,jemalloc核心数据结构,内存操作单位。
管理jemalloc内存块的结构(即分配给用户的虚拟内存块),每一个内存块大小可以是N * page_size (N >= 1)。一个extent可以用来分配一次large_class的内存申请,但可以用来分配多次small_class的内存申请,如果分配的是small_class,这时的extent也称作slab。
extent.e_bits:8字节长,记录arena_ind、zeroed、state、nfree等信息extent.e_addr:管理的内存块的起始地址extent.e_slab_data:当此extent用于分配small_class内存时,用来记录这个extent的分配情况,此时每个extent的内的小内存称为region
extent.e_bits中记录的state有四种情况。
typedef enum { |
arena
头文件include/jemalloc/internal/arena_*.h,arena是extent的管理者。
用于分配&回收extent的结构,在文件arena_structs_b.h中定义它的数据结构。默认使用四倍于逻辑CPU数量的arena来减少锁的竞争,各个arena所管理的内存相互独立,多个arena之间的内存是不可见的。每个用户线程会被绑定到一个arena上,它的所有内存申请释放行为都会被jemalloc转换为对此 arena 的操作。
arena.large:存放large_class的extentarena.bins[SC_NBINS]:heap,存放空闲regionarena.extents_dirty:存放用户调用free或tcache回收后的extentarena.extents_muzzy:存放extents_dirty进行lazy purge后的extent,dirty -> muzzyarena.extents_retained:存放extents_muzzy进行decommit或force purge后的extent,muzzy -> retainedarena.extent_avail:存放可用的extentarena.base:指向该arena的元数据base
arena中释放的extend标记了多种状态,清理过程被称为decay-based purging(基于衰变的清理)。
释放的extent如果曾被使用过,会有对应的物理内存分配,就认为是dirty的,如果一个固定周期内没被再使用,就移动到muzzy列表。如果一个固定周期内没被再使用会被purge,会转到retained列表中。retained里的就是完全用不到的extent了,直接释放掉留个统计数就好了。
当线程寻找一个合适的arena进行绑定时,会遍历arenas数组,并顺序挑选。
- 如果找到当前线程绑定数为0的arena, 则优先使用它。
- 如果当前已初始化arena中没有线程绑定数为0的,则优先使用剩余空的数组位置
构造一个新的arena。arenas数组遵循lazy create原则,初始状态整个arenas数组只有0号是被初始化的,其他位置都是null指针。通常随着新的线程不断创造出来,arenas数组也被逐渐填满。 - 如果前两条都不满足,则选择当前绑定线程数最小的,且位置更靠前的一个arena进行绑定。
size class
头文件include/jemalloc/internal/sc.h。
假设在64位系统上,页面大小为4 KiB,量子大小为16 bytes,每个类别中的大小类如表所示。

共有232个小类。如果用户申请的大小位于两个小类之间,会取较大的。比如申请14字节,位于8和16字节之间,按16字节分配,分为2大类:
small_class(小内存):对于64位机器来说,通常区间是[8, 14KiB]。为了减少内存碎片,并不都是2的幂。large_class(大内存):对于64位机器来说,通常区间是[16KiB, 7EiB],从4 * page_size开始,最大是2^62 + 3^60。
sc.index:size位于size_class中的索引号,区间为 [0,231]。例如4kb字节为28。
base
头文件include/jemalloc/internal/base_*.h。
arena的元数据,所有base组成一个链表。
bin
头文件include/jemalloc/internal/bin*.h,管理slab。
bin是一组slab类型的extent。
slab
当extent用于分配small_class内存时,称其为slab。一个extent可以被用来处理多个同一size_class的内存申请。
其他头文件
jemalloc
头文件include/jemalloc/internal/jemalloc*.h,jemalloc 核心接口。
atomic
头文件include/jemalloc/internal/atomic*.h,移植了C11中的atomic操作。
包括acquire等基本操作和bool、size_t、unsigned等一些基本类型的原子类型。
background_thread
头文件include/jemalloc/internal/background_thread_*.h,后台线程。
后台线程用于内存的自动回收,可以主动的启停。
tsd
头文件include/jemalloc/internal/tsd*.h,Thread-Specific-Data,每个线程独有,用于存放与这个线程相关的结构。
tsd.rtree_ctx:当前线程的rtree context,用于快速访问extent信息tsd.arena:当前线程绑定的arenatsd.tcache:当前线程的tcache
tcache
头文件include/jemalloc/internal/tcache*.h,tcache是每个线程独有的缓存(Thread Cache),大多数内存申请都可以在tcache中直接得到,避免加锁。
tcache.bins_small[SC_NBINS]:小内存的cache_bin
cache_bin
头文件include/jemalloc/internal/cache_bin.h,每个线程独有的,专用于分配小内存的缓存。
cache_bin.low_water:上一次GC后剩余的缓存数量cache_bin.ncached:当前cache_bin存放的缓存数量cache_bin.avail:可直接用于分配的内存
pages
头文件include/jemalloc/internal/pages.h,内存页的操作。
工具函数
均在 include/jemalloc/internal/ 目录下
assert.h,自定义断言,减少断言失败后死锁的可能性bit_util.h,位操作ctl.h,控制函数入口emitter.h,用于输出log.h,日志输出hook.h,定义 extent 的 hook 方法(非常实验性的API,可能会被删除)mutex*.h,锁实现nstime.h,时间相关函数prof*.h,性能分析相关实现quantum.h,定义用于对齐的宏LG_QUANTUMsafety_check.h,安全性检查相关stats.h,状态统计和打印相关sz.h,内存大小计算和转换相关test_hooks.h,用于测试对libc的hook效果ticker.h,时间ticker类util.h,各种工具函数witness.h,死锁监控
算法实现
均在 include/jemalloc/internal/ 目录下
bitmap.hckh.h,Cuckoo Hashhash.h,基于MurmurHash3div.h,比CPU除法更快的实现ph.h,Pairing Heap实现。配对堆是一种多叉树,并且可以被认为是一种简化的斐波那契堆。(From wikipedia)prng.h,线性同余伪随机数生成器rb.h,实现left-leaning 2-3 red-black treertree*.h,实现Radix Tree,专门为将元数据与jemalloc当前拥有的extent关联起来而定制的。seq.h,顺序锁(seqlock)实现smoothsteps.h,实现S函数曲线(sigmoidal curve)的回收图像,将一个回收周期拆分为200步spin.h,自旋等待
其他设计
见参考链接,基于5.1.0版本,结合5.2.0版本的ChangeLog看。
博客(2011)和视频(2015)
安装测试
下载最新source code压缩包解压。
cd jemalloc-5.2.1 |
安装成功后编写测试代码testjemalloc.c:
|
使用gcc testjemalloc.c -o testjemalloc -ljemalloc -lpthread编译,然后将jemalloc安装目录下的lib路径追加到文件/etc/ld.so.conf,再执行ldconfig,就可以正常运行测试程序了。
以上代码创建16个线程,每个线程分配大小分别为50000和20000的内存块(都是large),并输出分配统计。
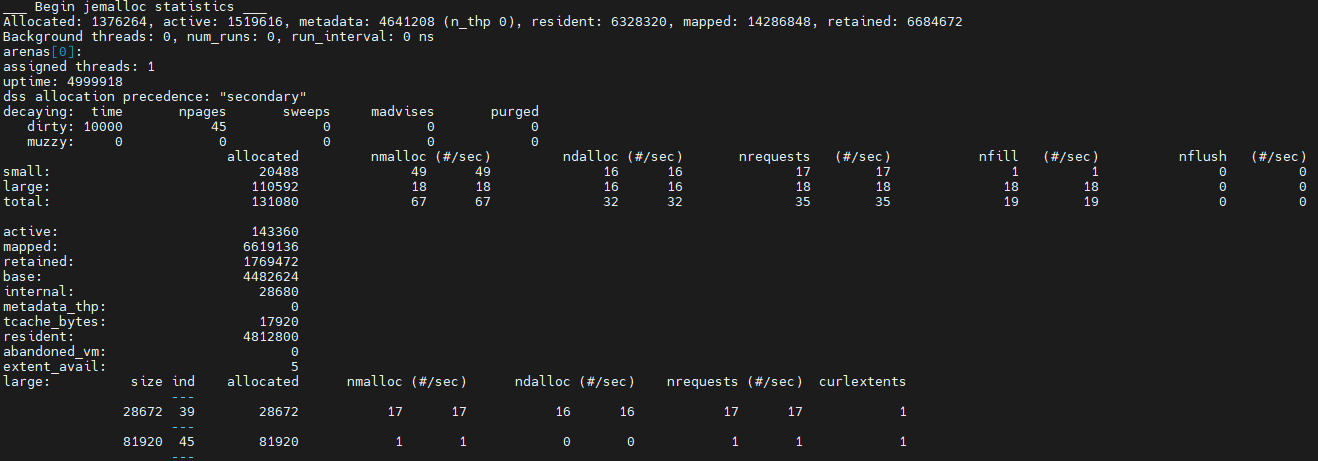
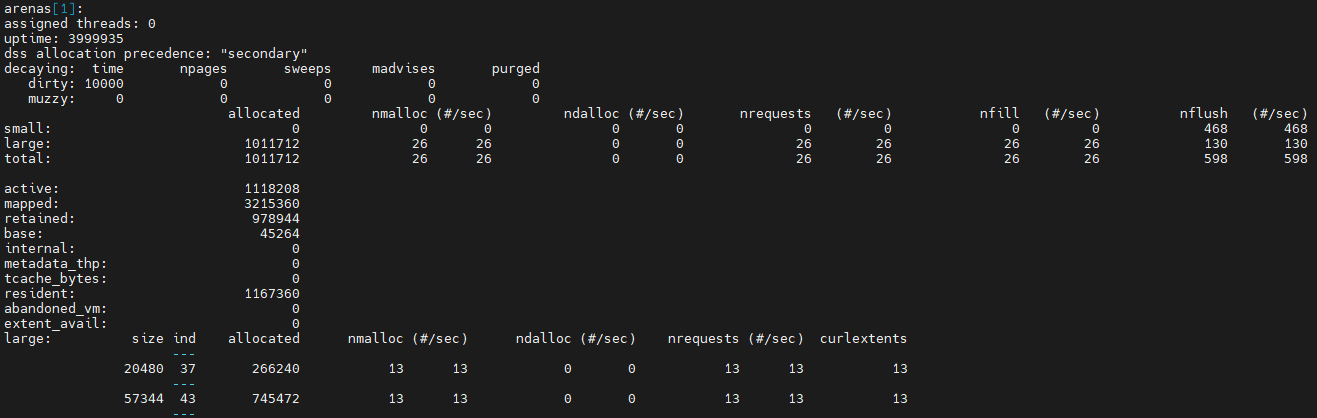
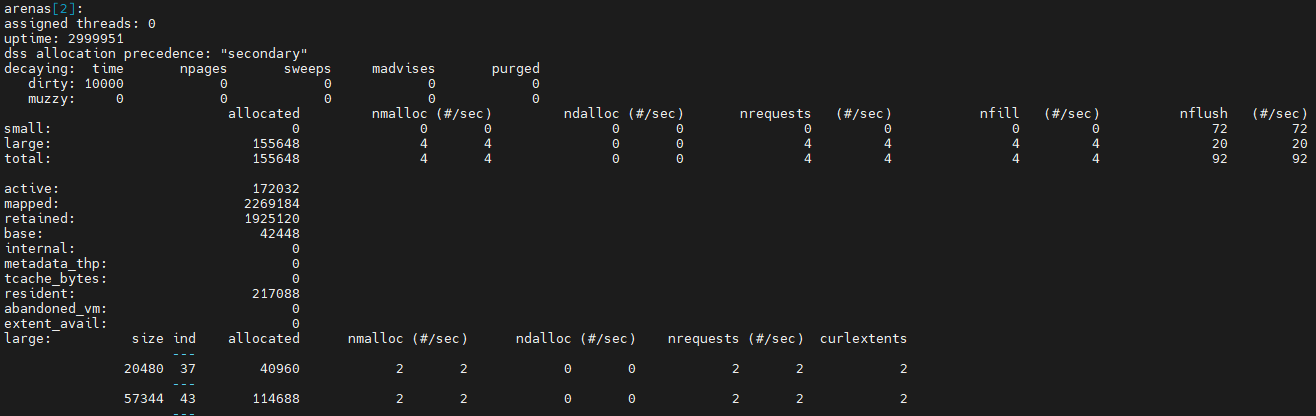
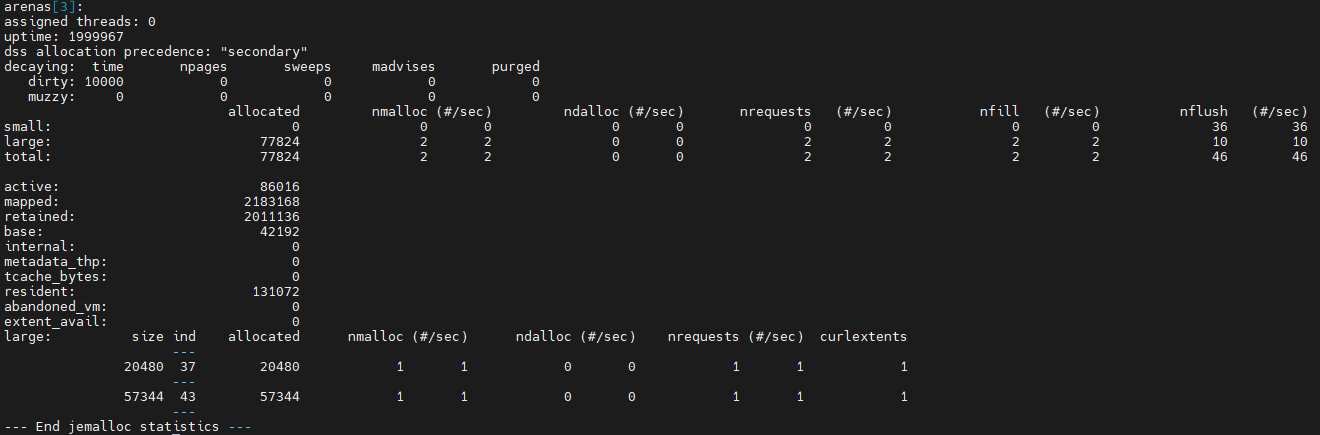
可以看出,arena[0]仍然有一个线程绑定,创建出来的剩下三个arena则已没有线程绑定,因为工作线程已经销毁。对于大小为20000的申请,会分配大小为20480的块,index为37;对于大小为50000的申请,会分配大小为57344的块,index为43。可以看出,arena[1]各使用了13个大小为20480和57344的块,说明工作过程中有13个线程曾经被绑定到该arena。以此类推,arena[2]是2个,arena[3]是1个,相加共16个工作线程。
 alipay
alipay